AI(人工知能)の用語解説記事は星の数ほどネット上に存在する。そのなかでも、機械学習、教師あり学習、教師なし学習、深層学習は多くの人が語っている。だが、その学習シリーズのなかで唯一、強化学習の説明はあまり多くない。
なぜ強化学習は人気がないのだろうか。ビジネスパーソンは強化学習について知らなくてもよいのだろうか。
もちろんそのようなことはない。深層学習を文字通り強化しているのが強化学習だからだ。この機会に、強化学習の基礎を押さえておこう。応用事例もあわせて紹介する。
続きを読む強化学習とは「教師あり・なし学習の仲間」
機械学習には「学習三きょうだい」がいる。教師あり学習、教師なし学習、強化学習である。深層学習も機械学習の一種だが、この三きょうだいとはやや毛色が違う。
したがって強化学習は、教師あり学習と教師なし学習と比較しながらみていくと、その実像を捕らえやすくなる。
「入力と出力」「法則の発見」「価値の最大化」の違い
教師あり学習、教師なし学習、強化学習の三きょうだいは、それぞれ仕事が違うと理解してもよいだろう。
教師あり学習は、「この大量の胃のCT画像のなかから、微小がんを発見せよ」という仕事に向いている。
教師なし学習は、「この膨大な顧客の購買履歴から、10種類の客層をわけよ」という仕事に向いている。
そして強化学習は「最適な株式投資の方法を考えなさい。ただし、損失を出す月があってもいいが、1年のトータルで儲けを出すようにしなさい」という仕事に向いている。
なぜそれぞれの学習に異なる仕事が割り当てられているのだろうか。
教師あり学習では、人の教師がAIに「これが胃がんの写真である」「これは胃がんの写真ではない」と教えて胃がんのCT画像を認識させる。こうして教師あり学習のAIは、胃がんを発見できるようになる。
そして人では胃がんかどうかわからない胃のCT画像を、教師あり学習AIに渡すと、胃がんのあるなしを判定できるようになる。
教師あり学習では、「入力と出力」が存在する。この場合の入力とは、胃がんかどうかわからない大量の胃のCT画像で、出力は胃がんのCT画像の抽出である。
教師なし学習は、混沌のなかに隠された「法則」を見つけ出す。例えば、大量のビッグデータは存在するものの、あまりに情報が多すぎて人にとっては混沌でしかない場合でも、それをそのまま教師なし学習AIに入力すると、似た特徴がある情報の集合をいくつかつくってくれる。マーケティングの分析作業には、教師なし学習が向いている。
教師あり学習のキーワードは「入力と出力」、教師なし学習のキーワードは「法則の発見」である。では強化学習のキーワードは何かというと「価値の最大化」だ。
単に価値を付けたり価値をみつけたりするのではなく、価値を大きくして最大にするのが強化学習の役割である。
例えば非強化学習型のAIでも、明日の株式相場で最も利益が出そうな銘柄を推測させることができる。当たるかどうかはAI開発者の腕次第であるが、AIに読み込ませる指標を多くすれば、理論上は当たる確率が高くなる。
しかしそのAIに、現在の株式資産を1年間で1.3倍にせよと命じても、推測することは不可能だろう。なぜなら株式投資で長期的に利益を出すには、時折、損を出す必要があるからだ。
株式投資をする人たちは、保有する株の価格が急落したら急いで売る。これを損切りという。しかし株式投資で財をなしているごくわずかなスーパー投資家たちは、ときに株価が急落しても売らないことがある。それは、再上昇すると読んでいるからだ。損切りをしてしまう損失が確定してしまうが、急落しても売らず、その後上昇すれば利益を挙げることができる。
普通のAIは、単純に利益を出す方法なら提案できるが、「損して得取れ」の思考を持つことは簡単ではない。それを可能にするのが強化学習だ。
なぜ強化学習は損して得取れができるのだろうか、つまり、価値の最大化をどのように目指しているのだろうか。
次の章で詳しく解説する。
強化学習の仕組み
強化学習では、【状態】と【行動】と【価値】をAIに与えることで、価値の最大化を目指す。この記事では、一般的な状態・行動・報酬と区別するため、強化学習については【状態】【行動】【価値】と表記する。
【状態】を別の言葉で置き換えると、環境や条件である。例えば株の売買で価値の最大化を目指すのであれば、企業業績や経済情勢や為替、原油価格、米中貿易戦争などが【状態】になる。
【行動】とは、強化学習AIユーザーの行動のことであり、例えば株を買ったり売ったりすることである。強化学習はユーザーに【行動】を提案する。
そして【価値】とは、ユーザーが強化学習AIの予測にしたがって行動したことで得られる果実である。例えば、強化学習AIが「その株は今が売り時」と予測して、ユーザーが株を売って利益を得れば、それが【価値】となる。
強化学習開発で重要になるのは、【価値】を一般的な価値に設定するのではなく、【最大の価値】に設定することである。
ではどのように【価値の最大】を獲得していくか。
【状態A】のときに【行動A】を取ったときの【価値A】より、【価値B】のほうが価値が大きければ、【状態A、行動A】を捨てて【状態B、行動B】に移行するする。
この過程を繰り返していけば、理論上は【最大の価値】を獲得できるようになる。
強化学習の応用事例
それでは次に、強化学習の応用事例をみていく。現代AIの認知度を一気に世界に知らしめた囲碁AI「アルファ碁」には強化学習が使われている。
そして、電気自動車テスラや宇宙ロケットのスペースXの創業者であるイーロン・マスク氏が協力している非営利団体のロボットハンドも強化学習によってこれまでにない動きを獲得することができた。
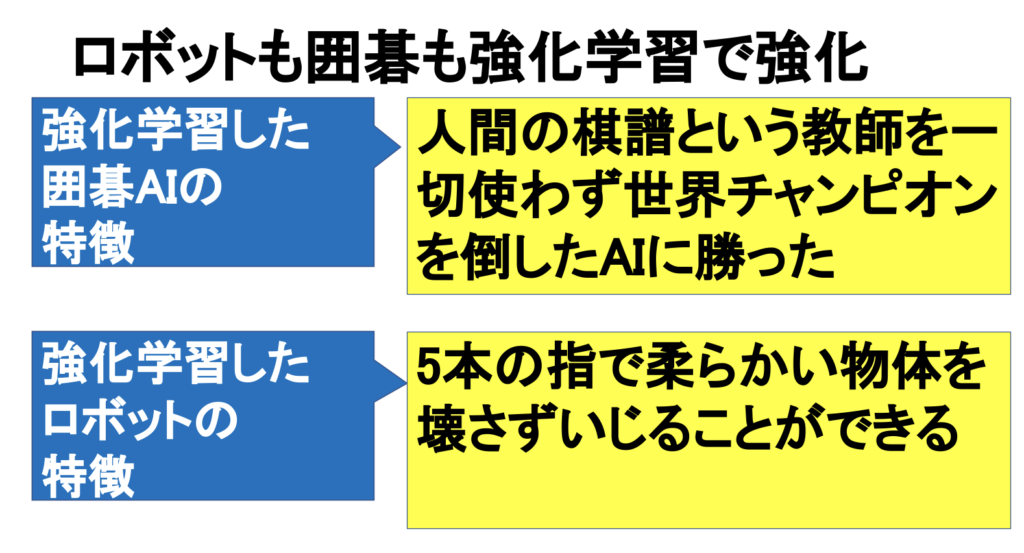
世界1の教師あり学習AIを完全に倒した
グーグルによって買収されたディープマインド社はまず、アルファ碁ゼロの前身であるアルファ碁をつくった。アルファ碁はそれでも十分強く、世界王者たちを倒していった。
アルファ碁がそれだけの力を持つことができたのは、ディープマインド社がそれだけ鍛えたからだ。ディープマインド社は、教師あり学習AIを2つつくり、それらに囲碁をさせて「勝手に学習」させた。
そしてアルファ碁の進化版であるアルファ碁ゼロは、教師あり学習を用いず、強化学習の一種である深層強化学習だけでつくった。つまりアルファ碁ゼロは、人間の棋譜を参考にせず「自分流」で囲碁を学んでいったのである。
その結果、アルファ碁ゼロは、アルファ碁に全戦全勝するまでになった。囲碁の世界ではもはや、人間VS人工知能の闘いは終わったといえるかもしれない。例えば陸上の100メートル走で、人がバイクと競争しないのと同じである。
報酬だけで人間の能力を獲得した?
イーロン・マスク氏が協力したのは、非営利団体OpenAIで、ロボットハンドを開発している。OpenAIが開発したシステムは、コンピュータ上でシミュレーションした手の動きのデータを、実際のロボットハンドに送り続けるようになっている。
その結果ロボットハンドは、手のなかのサイコロを自在にくるくる回転させられるようになった。
この開発のポイントは、ロボットハンドに「サイコロをくるくる回転させろ」と指示しているわけでも「このようにくるくる回転させろ」と教えているわけでもない点である。
人間がしたことは、ロボットハンドが少しでもサイコロを回転させたら報酬を与え、サイコロを落としたら何も与えない、ということだけだ。
「ロボットハンドのなかのサイコロ」という【状態】のなかで、ころころ回転させる【行動】をしたときに報酬という【価値】を与えているので、これは強化学習による学習である。
つまりこのロボットハンドは、強化学習によって独自のサイコロころころ回しを「発明」してしまった。
そして驚くべきことに、ロボットハンドが独自に発明したサイコロころころ回しの動きは、人によるサイコロころころ回しの動きと酷似している。
強化学習が、報酬だけで人の能力を獲得した。
強化学習の課題と今後
強化学習の研究者たちは、強化学習AIが教師あり学習や教師なし学習を必要とせず成長できる点に将来性を感じているようだ。教師あり学習AIや教師なし学習AIを賢くさせるには、膨大なデータが必要になる。そのデータは人間が集めなければならない。
ところが強化学習AIは、自分がいる【状態】の環境や条件から学び取っていく。人間はときどき報酬を与えるだけだ。
ところがそれが強化学習を強化させることのネックになっている。それは、自分の力だけで環境から学び取る学習法は、時間がかかるからだ。
今後は、強化学習が短時間で環境データを集める方法や、少ない環境データで効率よく学習する方法などを研究していくことになる。
まとめ~より人に近付く
教師なし学習も混沌のなかから法則をみつけるという点において、人間らしいといえる。なぜなら人は常に混沌状態に意味を見出してきたからである。
一方の強化学習も、環境や条件のなかで価値を最大化させる点において、人間らしい。人間はこれまで、地球という厳しい環境のなかにいながら、生きるという価値を最大化させることで進化してきたからである。
この記事ではほとんど言及できなかったが、深層学習は人間の脳を模してつくっている。
AIは人間らしさをとことん追求して人間を超えていく。

<参考>
- 強化学習入門 ~これから強化学習を学びたい人のための基礎知識~(Platinum Data Blog)
http://blog.brainpad.co.jp/entry/2017/02/24/121500 - 人工知能・機械学習・脱ブラックボックス講座(Udemy)
https://udemy.benesse.co.jp/ai/reinforcement-learning.html - 第2回 強化学習が注目されている理由と応用事例(Manatee)
https://book.mynavi.jp/manatee/detail/id=87889 - このロボットハンドは、強化学習で人間の動きを“発明”した(WIRED)
https://wired.jp/2018/08/20/robot-hand-grab-like-human/ - 先端AI技術を活用した新たな価値あるサービス共創を目指して(第3回 SHIBUYA SYNAPSE)
https://shibuya.ai/report/03/
役にたったらいいね!
してください
No related posts.






