画像認識技術とは画像として表現されている情報を認識する技術である。
AIの発達に伴い画像認識精度が向上し、様々な分野注目され、メディアでも取り上げられている。
画像認識とは人間での視覚情報処理に相当することであり、コンピュータによる画像認識の精度が人間並み(もしくはそれ以上)になったということは、基本的な視覚情報処理については人間相当の知能、つまり人工知能を実現したと言えるであろう。今後は、自動運転、物流、防犯、医療などの多くの分野で応用され、社会実装が急速に進むと予想されている。
例えば、Amazonが米国で展開しつつあるAmazon Goは、誰が、何を手にしたかをカメラ画像によって認識し、店舗から出店の際に自動で決済処理をするという先進的なレジなしコンビニエンスストアである。日本でもファミリーマートやJR東日本でも同様の店舗の実験が進められている。また、中国では、主要な都市にはいたる所に監視カメラが設置され、画像認識技術を用いてリアルタイムで監視・警告が行われていると言われており、未来の監視社会の予兆ではないか懸念されている。
続きを読む
以下では、それらの基盤となる画像認識技術とはどのようなものなのかを解説する。

画像認識技術の概要
画像認識とは、画像として表現されている、以下のような情報を認識することを指す。
・物体情報(名称、個数、色、移動など)
・人物情報(名称、人数、属性(性別、表情、年齢)など)、
・物体・人物位置
・物体状態
・人物位置・姿勢
・異常箇所
応用例には、入出国審査、コンサート入場確認やスマホでの本人確認ための顔認証、マーケティング調査で利用されている動線解析、20年以上前から実用化されているOCRなどがある。将来の可能性としては医療画像による病気診断、不良品判断などの異常検出、自動運転おける周囲認識などがある。技術的基本は、画像を構成する画素RGBの並びを要素とした画像ベクトルの数値解析がメインとなる。
画像認識技術の仕組みと原理
画像認識技術の仕組みは、画像認識の前に処理すべきデータ量を大幅に削減し、コンピューターが画像を認識しやすくする画像処理を行う。画像処理は主に以下のような手順になる。
・画像のノイズや歪みなどを取り除く。
・オブジェクトの輪郭を強調したり、明暗や色合いを強調し特徴を取り出しやすくする。
・画像からオブジェクトの領域を切り出す(領域抽出)
以下にオブジェクトの輪郭や明暗や色合いを強調する方法を以下に示す。
表1 画像処理の方法
| 項目 |
概要 |
検出対象 |
| エッジ検出 |
画像の明暗が不連続に変化している箇所を特定 |
・物体の境界検出
・面の向きの変化の検出 |
| コーナー検出 |
2つの方向が異なるエッジが近傍に存在する箇所を特定 |
・強度の極大、極小点の検出
・曲線の終点の検出 |
| 記述子 |
大きさと回転に対して不変な特徴量を求める |
・画像の勾配強度と方向算出
・勾配方向ヒストグラム作成 |
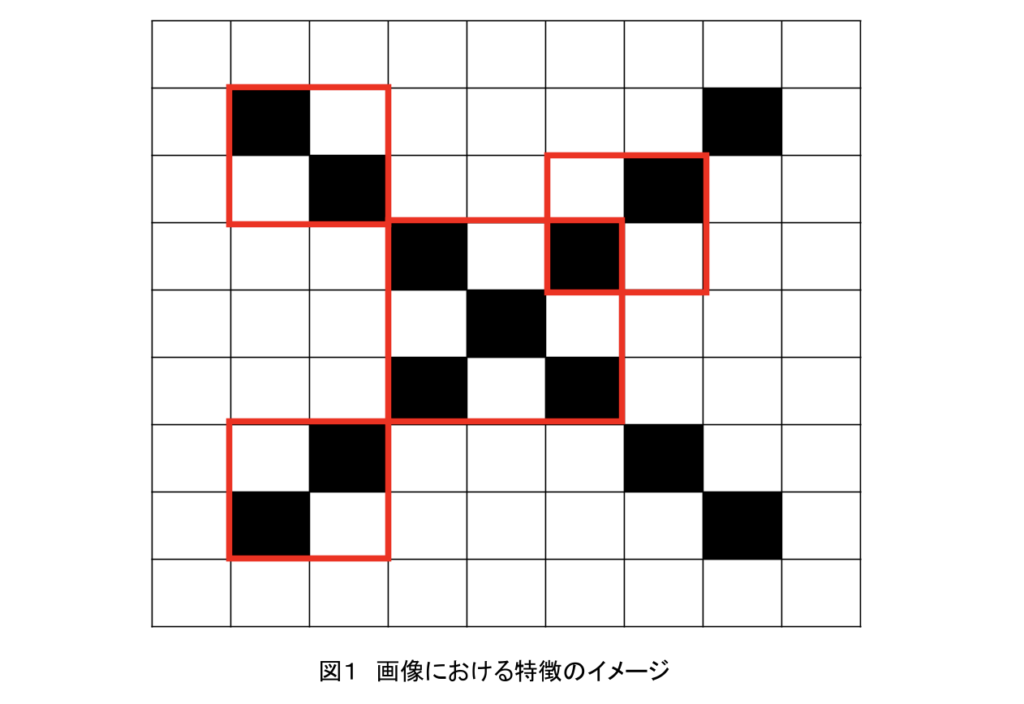
画像処理に続く画像認識は、特徴抽出処理により画像に表現されている「特徴」と呼ばれるある画素の周辺にある共通の画素の並びを検出し、さらにその特徴がどこにあるかを検出する。例えば、図1に示す。「X」という画像の特徴は、対角線と交差であり、この2つにより画像は構成されている。検出された特徴は教師データの特徴をパターンマッチングされラベル付けされる。
ディープラーニングとの関係性
ディープラーニングが注目されるきっかけとなる成果は画像認識での誤り率低減にあったが、そのディープラーニングの画像認識には、畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)またはConvNetと呼ばれる技術が大きく関係している。CNNは対象画像のどこに特徴が含まれているか判別するために、すべての画素で特徴の比較し、一致点を検出する。CNNでは特徴の検出と合わせて、特徴の位置の検出も行う。
CNNには、畳み込み(Convolution)と位置不変性(Translation Invariance)と合成性(Compositionality)の3つの性質がある。
◼️畳み込み
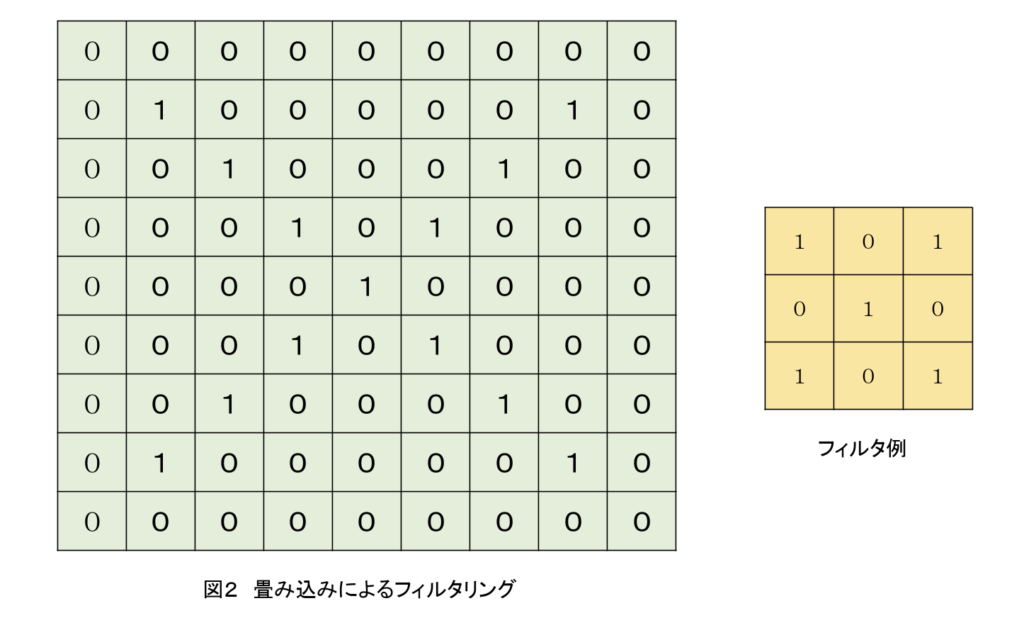
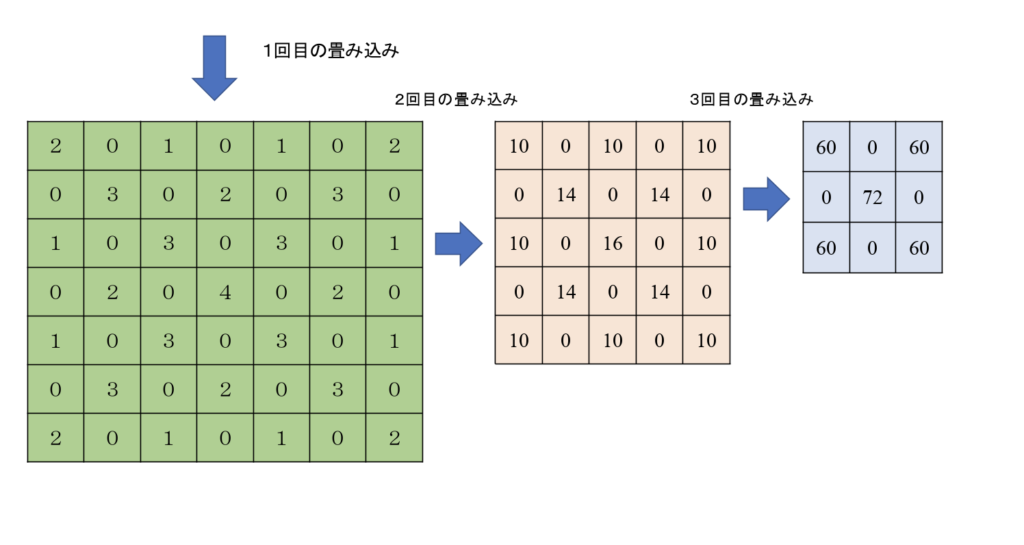
畳み込みは、フィルタリングにより全領域で特徴の比較と一致点の検出をする。図2に畳み込みによるフィルタリングの例を示す。フィルタリングでは、左上から順に1画素ずつ移動させながら畳み込み処理を行う。この例のフィルタは、フィルタに応じた数を画素に積算しフィルタ内の全画素分を加算し、新たな要素としている。この例から、フィルタリングを繰り返すことにより、元の画像の特徴を定量的に抽出できることがわかる。図の様に画像に畳み込みフィルタを施した結果を特徴マップと呼ぶ。
�
◼️合成性
CNNは画像を構成する特徴の構成を抽出するとともに、それらを組み合わせて利用できる。
◼️移動不変性
CNNは局所領域からフィルタによって特徴を検出していくので物体の位置の変動にロバストである。これにより、特徴が画像のどこにあっても検知することができる。
画像認識技術の進化
ディープラーニングの登場以来、年々画像認識技術は急速に進化しており、画像認識コンテスト「ILSVRC(ImageNet Large Scale Visual Recognition Challenge)」で記録された現在の画像認識の誤り率は人間が認識した場合の誤り率と言われている5.1%を下回る4%台となっている。
また、画像内に表現されている複数の物体とその位置をリアルタイムに認識する物体検出アルゴリズムも進化している。YOLO v3(You Only Look One)やSSD(Single Shot MultiBox Detector)のような、軽量で1秒間に処理可能な画像枚数(フレームレート)が大きいアルゴリズムが研究・開発されている。物体検出は、自動運転やロボテックスにおいて周囲の環境をリアルタイムに高精度で認識するための利用が期待されている。
現在のCNNによる画像認識技術の課題は、配置などの空間構造を認識していないため特徴のレイアウトが異なると違う対象物と認識できないことである。また、対象物の回転、反転、縮小などの教師データ画像と配置が大きく異なる画像に対しては精度が劣化するという課題もある。それに対する対策としては、教師データ画像に対して擬似的な回転、反転、縮小などの前処理を施し、水増しという形で教師データ画像を非常に数多く準備・学習する必要がある。この点が人間と比較して学習に大量のデータと学習時間と計算機パワーが必要となる制約の原因になっている。それを改善するためにCapsNet(Capsule Network)と呼ばれる新たなネットワークモデルが2017年にヒントン教授らによって示された。
CapsNetは、ひとことで言うと、画像内の対象物の空間情報をカプセルと呼ばれるベクトルで保持することを特徴とするネットワークである。その効果を示すため、MultiMNISTデータ・セットにある複数の手書き文字を重ねて表現した画像に対して高精度に文字を分離し、それぞれを認識できることが示されている(図4)。現段階で示されている応用例は、複数手書き文字だけであるが今後様々な分野で利用されていくと予想されている。
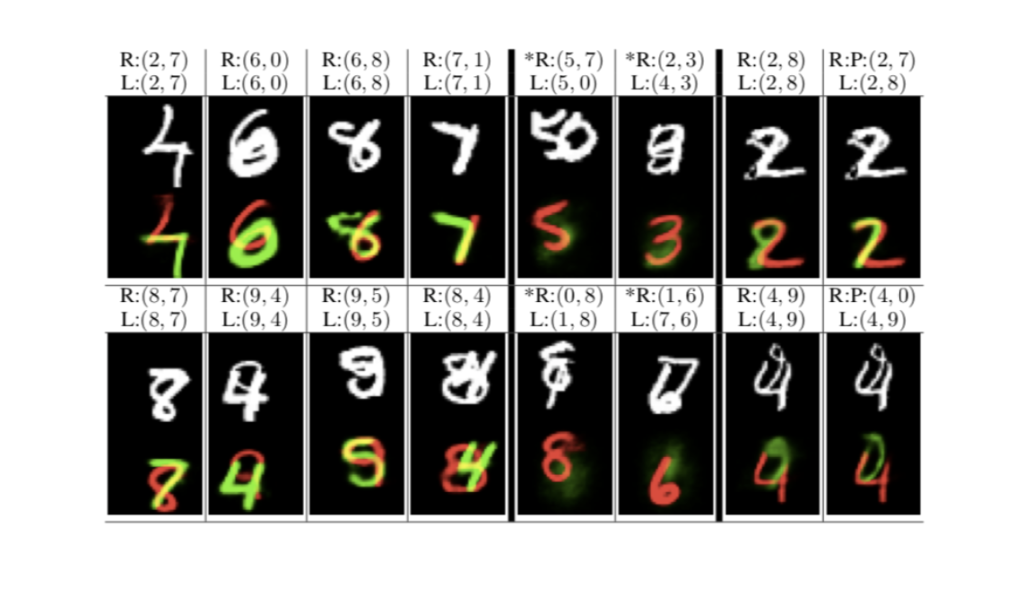
図4 MultiMNISTの分離結果
(Sara Sabour, Nicholas Frosst, Geoffrey E Hinton, “Dynamic Routing Between Capsules”,より)
まとめ
画像認識技術とは文字通り、画像として表現されている情報を認識する技術である。画像認識技術はディープラーニングの登場によって急速に進化している。画像認識技術は、物体検出、医療画像診断、異常検知など面で、高精度、高速化が図られ私達の将来の生活を大きく変える可能性を秘めている。
<参考>
- 定番のConvolutional Neural Networkをゼロから理解する(DeepAge)
https://deepage.net/deep_learning/2016/11/07/convolutional_neural_network.html
- カプセルネットワークはニューラルネットワークを超えるか。(Qiita)
https://qiita.com/hiyoko9t/items/f426cba38b6ca1a7aa2b
- Sara Sabour, Nicholas Frosst, Geoffrey E Hinton, “Dynamic Routing Between Capsules”, NIPS(2017), 2017, Available at
https://arxiv.org/pdf/1710.09829.pdf.
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。