最近、筆者がTVでみたドラマのシーンの中に、女優がスマホに向かってメモ的な情報を音声で吹き込み、瞬時にその情報がテキストデータ化されスマホの画面に表示されるというシーンがあった。また、バラエティ番組でも視聴者投稿として、夫が「OK、(妻の名前)、テレビつけて」と言ったら妻が怒った、という投稿が紹介された。このようなコンテンツが制作され放送されるということは、どちらも音声認識がすでに一般的な場面にて利用され入力方式として一般化しつつあることの現れであると思われる。ここでは、音声認識技術の概要について説明する。

音声認識技術とは
音声認識技術とは、人間の音声をコンピュータが認識し、文字列に変換したり、音声の特徴をとらえ、話者の特定をしたりする技術である。近年では、スマートフォンの音声入力やAIスピーカーの音声応答のような機能も音声認識技術を基に開発・実行されている。
音声認識技術の歴史
音声認識技術は60年ほど前より研究が開始された。実用化という点では、日本国内では、1990年代より商品化が進められており、企業にかかってきた電話に対する簡単な応答ができるソリューションや、PCの一般普及に合わせて音声入力を可能にする個人向けソフトウェア販売などが開始されてきた。しかし、まだ認識精度という面でユーザの要望を満足できる精度に達しておらず普及には遠いと言う状況であった。2000年代に入り、後述する機械学習アルゴリズムの進化により認識精度が格段に向上するに伴い、カーナビやテレビの音声入力手段として本格的に普及が始まった。2010年代に入ると音声入力だけでなくiPhoneに搭載されたSiriやGoogle アシスタントの様なインタラクティブな応答や処理を返す音声アシスタントサービスが開始され普及しつつある。
どのような仕組みで音声を認識しているのか
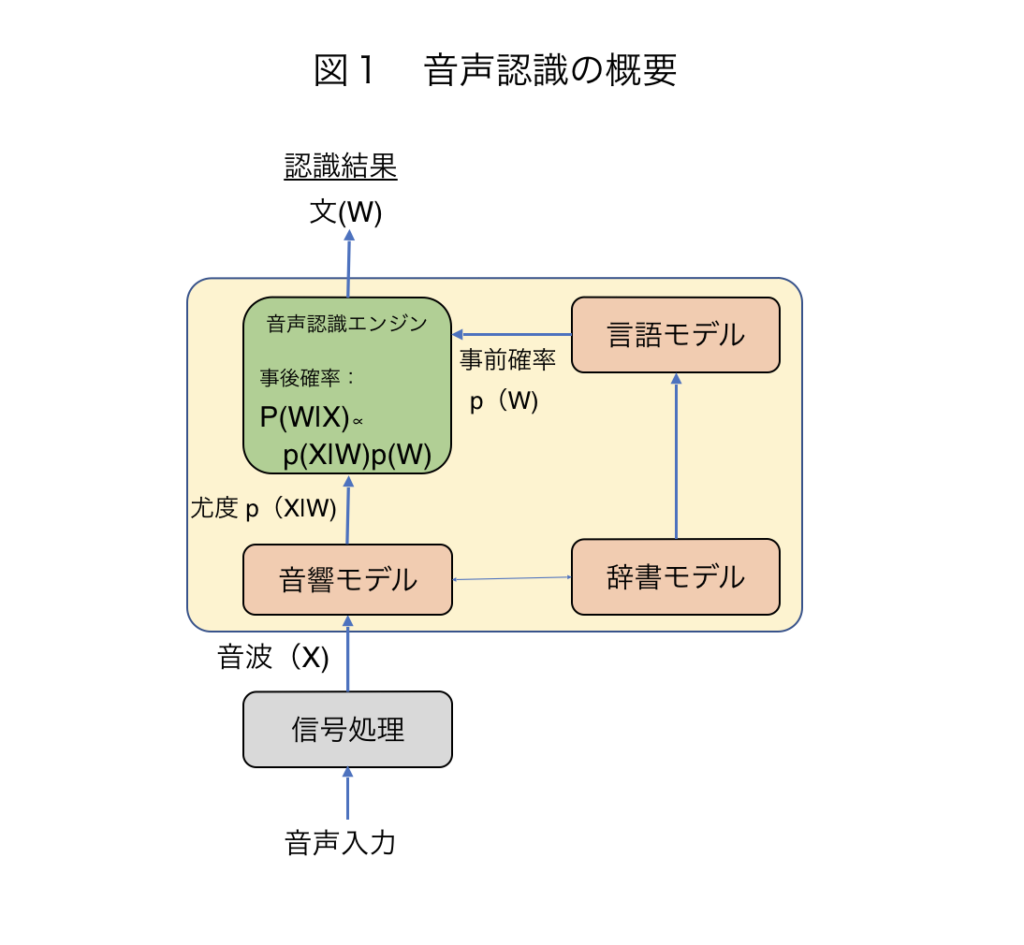
音声認識の仕組みは、図1に示すように大きく分けると以下のような流れによって構成される。
- 音声入力
- 信号処理によるノイズ処理
- 音波から音素を特定
- 音素の並びを単語に変換
- 単語の並びを文に変換し、テキスト出力
(図: 音声認識技術の変遷と最先端 河原達也(京都大学) より参考)
技術の基礎となるベイス推定理論で表現すると、観測された音声を信号処理し雑音などを除去した音波信号をXとして、求めるべき文(文字列)をWとすると、音声Xが観測された条件の基に文がWとなる確率密度関数p(W|X)は以下の式で表現される。p(X|W)を尤度、p(W)を事前確率そしてp(X)をエビデンスと呼ぶ。音声認識とは、事後確率p(W|X)が最大となるW( = argmax p(W|X))を求める問題となっている。
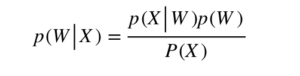
これらの処理は階層構造であり、それぞれの出力は次の階層の入力となっており、音素→単語→文というように表現が高度化していく。以下に各処理内容について概要を示す。
音響モデルによる音素認識
音素認識では、音響モデルを用いて音波の周波数成分や時間変化を分析し、その音声の波形から一音一音を切り出し、その特徴量をそれぞれの言語の基本となる音素をパターンマッチングにより特定する。パターンマッチングの手法は、2000年代までは確率的手法であるGaussian Mixture Model- Hidden Markov Model(以降、GMM-HMM)が一般的であったが、2010年代になってからはGMMの確率計算をディープニューラルネットワーク(DNN)に置き換えたDNN-HMMが一般的になっている。各種の音声認識タスクにおいて、GMM-HMMに比較しDNN-HMMが高精度(約20~30%の誤り率削減)になることが示され、用いられるようになった。その後も、様々なニューラルネットワークを多層に積み重ねるなどの改良が行われている。
DNN-HMMの構成イメージを図2に示す。音響の特徴量がDNNの入力層に入力され、DNNの出力層のノードが、HMMの各状態に対応付けられる。HMMによる音声認識で必要となるのは、尤度であるが、DNNで計算される出力確率は通常、事後確率となるので、事前確率で除算してHMMに渡す。
(図: 音声認識技術の変遷と最先端 河原達也(京都大学) より参考)
辞書によるパターンマッチング
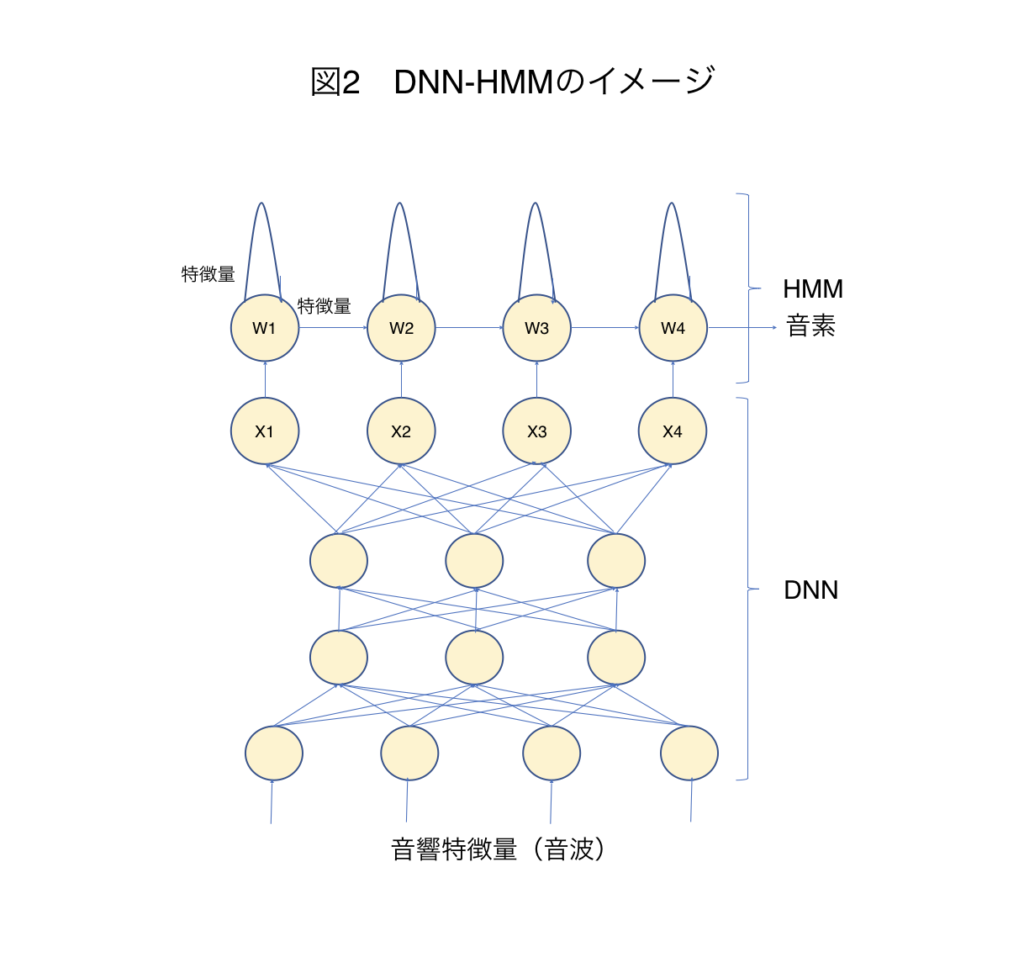
音素を特定後、その音素の並び応じて予め構築された辞書とパターンマッチングを実施し、単語としての文字表現をする。図3に示すようにパターンマッチングの探索効率を上げるために、辞書のデータ構造は通常、木構造のデータ構造が用いられる事が多い。前段階の音声を音素に変換する部分の精度が100%ではなく、音素への変換で認識ミスが起こる可能性も十分あるが、単語に変換する際に、もっともそれらしい単語を選ぶことで音素変換の誤りを補正することが可能となる。
(図: 音声認識技術の変遷と最先端 河原達也(京都大学) より参考)
言語モデルによるパターンマッチング
言語モデルは、図4に示すように前の単語のつながり状況に基づき最も確率が高い組み合わせを求める。言語モデルには、当初はN-gramが利用されていた。N-gramとは、ある単語が出現する確率はその(N−1)前までに出現した単語に依存するというモデルである。Nは任意の数字を指すが、一般的には N=3のTri-gramの精度が高いことが知られている。

(図: 音声認識技術の変遷と最先端 河原達也(京都大学) より参考)
近年では、音響モデルだけでなく、言語モデルにおいてもRecurrent Neural Network(ニューラルニューラルネットワーク:RNN)の導入が進められている。ただし、N-gramモデルの方が低頻度語について確率的な単語出現の平滑・補間が効果的に行えるため、RNNとN-gramモデルを併用する場合が多い。
RNNの実装アルゴリズムの一つとして、種々のゲートを導入した LSTM (Long Short-Term Memory) がある。LSTMでは、内部メモリで1つ前の単語の出現状態を記憶しつつ、記憶とともに単語情報を入力、出力の各過程においてゲートを設定し、情報の学習・制御を行っている。このゲートの値も入力と1つ前の出力を元に決まるように学習される。
この様に、音波から音素、音素から単語、単語から文というように、階層的にそれぞれのアルゴリズムによって処理することで、音声認識は、音からテキスト文字を認識することが可能になる。また、音声認識技術は、この様に階層的に処理を実施し、音から文を導くことによりありえない大きく誤った認識をすることを回避している。
音声認識の精度
最近の音声認識の精度に関する話題として、IBMとMicrosoftが電話会話音声認識で約95%の認識率を達成し、「人間と同等の認識精度を実現した」と発表したことが挙げられる。ただし、これは、雑音が少ない環境で、くだけた表現を含まず、かつ、明瞭な発音で話した場合である。実際に、スマートフォンの音声入力を雑音環境で早口で利用しようとした場面では何度トライしても認識されない、または認識精度が悪いことは読者の方々も実感されていると思う。余談であるが、筆者の話し方では、発話直後の滑舌が悪いらしく、発話直後の精度が格段に悪い。それでも、周りの人間が会話に不自由していないのは、相手の脳が認識している従来の音声パターンと、その前後の会話内容で自動的に補間しているからである。その意味では、まだまだ人間は機械に負けていないと言える。しかし、日々急速に認識アルゴリズムが進化しており、認識精度は急速に向上していくことが期待される。
まとめ
音声認識の普及に障壁と考えられていた認識精度もディープラーニングなどの機械学習技術の進展により大きく改善し、人間が持つ音声認識能力を超えたというデータもある。よって、音声認識は研究段階から実用レベルに達し、音声入力や音声アシスタントサービスとして一般家庭にも普及しつつある。今後は、AI、ロボットとの対話、コミュニケーションなど、様々な場面で利用されていくと考える。
<参考>
- 解説 音声認識技術の変遷と最先端 河原達也(京都大学)
日本音響学会誌第 74 巻 07 号 (2018)
http://sap.ist.i.kyoto-u.ac.jp/members/kawahara/paper/ASJ18-7.pdf - 音声認識の仕組みと、隠れマルコフモデル(HMM)入門
https://spjai.com/speech-recognition/ - 音声認識技術について
https://future-tech-association.org/2018/01/16/onse-ninshiki/
役にたったらいいね!
してください
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。






