音声合成とは、機械の声を人の声に似せてつくる技術のことだ。一方、音声認識は、テキスト(文字)を音声にしたり、音声をテキストにしたりすることをいう。音声合成と音声認識は全然別の技術ではないが、異なる点は多い。
音声合成技術については、「そのような技術は以前からあったはず」と感じる人もいると思う。しかし、AI(人工知能)を使った音声合成を体験すれば、従来の音声合成といまの音声合成がまったくの別物であると実感できるだろう。
まずは下記のURLを開いてみてほしい。
https://soundcloud.com/user-535691776/dialog
これは、カナダのAIベンチャーがつくった、ライアバード(Lyrebird)という音声合成ソフトのデモンストレーション音源だ。
オバマ前大統領とトランプ大統領とヒラリー氏が話をしているが、これはライアバードがつくった機械の声だ。3氏はこのような言葉を発したことがない。
なぜこのようなことができるのか、詳しくみていこう。

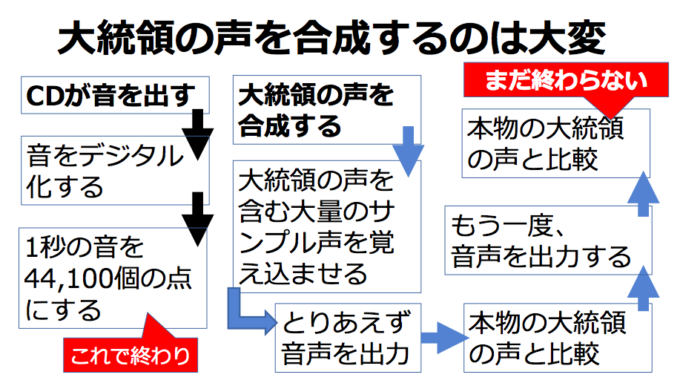
そもそも音のデジタル化とは
音声合成をみる前に、音のデジタル化について押さえておこう。
名古屋大学大学院情報学研究科の戸田智基教授は、音声や音楽、音環境の情報処理のスペシャリストだ。その戸田氏によると、音をデジタル化して再生するCDの音楽の音は、点の集合体になっているという。
音楽や人の声などの自然界に存在する音は、本来は点で分解できない。しかしそれではデジタル処理できない。それで音を極限まで細切れにして、その1点1点を機械で読むことにしのたである。
どれくらい細切れにしたかというと、1秒の音(音声、音楽)を44,100個の点にした。だから3分のポップ音楽だと点の数は7,930,000個(=44,100×60秒×3分)になる。
さらに音の1点1点を65,536種類の音に仕分ける。
つまり音のデジタル化とは、音のなかから1点を取り出し、その1点が65,636種類の音のどれに近いか認識し、それを「デジタルの音」とするわけだ。
つまり3分のポップ音楽を再生しているCD再生機は、「この1点の音は65,636種類の音のなかではこれに最も近い」という作業を、7,930,000回行っているわけだ。
かなり大きな数字が出てきたが、これはCD再生機の話にすぎない。だからAI技術は要らないし、IT技術もあまり必要ない。
しかしリアルな音声合成をつくりあげようとすると、もうAIをフル稼働させるしかない。
人の声は「ゆらぎ」が邪魔をしている
CDで音を再生するときにAIを使う必要がないのに、なぜ音声合成するときはAIが必要なのだろうか。
それは音声合成の目標が、任意の人の任意の音声を、特定の音質で再現することにあるからだ。一方、CDの目標は、CD内の情報を繰り返し再生できればよいだけである。
人の声には「ゆらぎ」が存在する。ゆらぎは変化を生む。このゆらぎのせいで、ある人が「ありがとう」と言い、5秒後に再び「ありがとう」と言っても、デジタルデータとしては異なる数値になってしまう。
しかし、ゆらぎは、大きな変化は生まない。つまり、ゆらぎが発生したからといって、まったく異なる声をつくるわけではない。
例えば、トランプ大統領がホワイトハウスで発した声の数値と、トランプタワーで家族と会話しているときの声の数値は違っているのだが、誰もが「あの怒声を発しているのは大統領だ」とわかる。
つまり音声合成で人の声をリアルに再現するには、「同じようで異なり」「異なるようで同じ」な声、つまり「ゆらぎ付きの声」を追い求めなければならないのだ。
ロボット声からの脱却にAIが必要になった
この「ゆらぎ付きの声」の再現に、グーグルが成功した。グーグルの音声合成技術は「ウェイブネット(WaveNet)」という。
先述の戸田教授は2018年3月に、あるメディアのインタビューで、ウェイブネットのようなものは出てくると思ったが、10年後ぐらいになると思っていた、と話している。
これはとても興味深い見解である。
戸田教授は音声合成の専門家である。だから、IT・AI企業がウェイブネットのような高性能な音声合成を開発することを見抜いていた。しかしそう簡単には完成しないと見積もっていた。
なぜかというと、音声合成を成し遂げるには、大量の人間の声と、大量の人間の声を短時間で処理できる賢いコンピュータが必要だからだ。戸田教授は、この2つを用意するのにあと10年でかかると考え、グーグルはその準備を10年前倒して行ったのである。
とりあえず人の音声を機械音でつくりだすだけなら、それほど難しくはなく、AIも要らない。ただそれだといわゆる「ロボットの声」になってしまう。「ご・しゅ・じ・ん・さ・ま・お・は・よ・う・ご・ざ・い・ま・す」といったふうに、たどたどしくなってしまうのだ。
そうではなく、あたかも大統領が話しているかのような機械音をつくろうとすると、途端に難易度が増し、AIが必要になる。
ロボットの声と大統領の声の合成の違いは、単純化するかどうかだ。音声合成を単純化していては、大統領の声に似ても似つかない声しかできない。
単純化とは、人間が「数理モデル」をつくることである。
1秒の音(音声、音楽)を44,100個の点にして、その1点1点が65,636種類の音のどれに当てはまるか判定していく作業は、数理モデルであり、単純なのだ。
トランプ大統領の声に似せる作業はこうだ。
AI音声合成に、トランプ大統領の声を含むたくさんの人の声を覚え込ませ、まずは1回、音声を出力させる。そしてAI音声合成に、「自分」が出力した声と本物のトランプ大統領の声の違いを計算させ、その違いを加味した音声を出力させる。この2回目の出力音声と本物のトランプ大統領の声の違いをまた計算させて、3回目の出力音声をつくらせる。――といった作業を、大統領の声に似るまで繰り返させる。この繰り返しこそAIによる「学習」である。
するとAI音声合成はあるとき急に、簡単にトランプ大統領の声を出せるようになる。こうなれば、AI音声合成を搭載したコンピュータに「私は歴代最高の大統領である」という文字を入力するだけで、トランプ大統領の声で「私は歴代最高の大統領である」と再生させることができるのである。
各社の開発競争は激化する一方
先ほど紹介したグーグルのウェイブネット(WaveNet)は2016年に発表された。
一方、冒頭で紹介した、オバマ前大統領とトランプ大統領とヒラリー氏の音声を合成したライアバード(Lyrebird)は2017年に発表された。
よって、ライアバードのほうが性能的には優れている。
ライアバードは1分間の本人の音声の音源があれば合成できる。さらに1,000字の文字を音声に合成するに0.5秒しかかからないという。
少し前までは、AI音声合成に「声真似」をさせるのに8時間分の本人音声を聞かせる必要があったことから考えると、隔世の感がある。
では、世界のグーグルが、ライアバードを開発したカナダのベンチャー企業に負けたのかというと、もちろんそのようなことはない。
グーグルは2017年12月に文字=音声変換システム「タコトロン2(Tacotaron2)」を発表した。これは最早、人の音声と区別できないほど流暢に話すという。タコトロン2はピリオドやカンマも認識して、人の音声が持つ時間性も再現するのだ。
音声を評価する基準にMOS(Mean Opinion Score)値があり、人間の音声のMOS値の平均は4.58点だ。タコトロン2の音声のMOS値は4.53点と、それとほぼ変わらない。
日本企業の音声合成技術もすごい
以上、海外の音声合成技術を紹介してきたが、日本企業も負けていない。
東京都文京区に本社を置く株式会社エーアイの「AIトーク」は文字情報を人の声にするだけでなく、感情を込めた音声にすることもできるまた、大人の男性の声や若い女性の声、3歳児の声にすることも可能だ。
例えば「ありがとうございます」という文字を入力し、「怒り」「悲しみ」「喜び」のいずれかを選んで「合成」ボタンを押すと、選んだ感情がこもった声がつくられて出てくる。
つまり「怒り」を選ぶと、ありがた迷惑な仕打ちを受けたときの「ありがとうございます」になるし、「喜び」を選ぶと、心から感謝している「ありがとうございます」になる。
このデモンストレーションは、以下のURLで体験できる。
https://www.ai-j.jp/demonstration/
AIトークはすでにさまざまな企業や機関が導入している。
株式会社セガ・インタラクティブは、ゲームのなかの登場人物の声にAIトークの技術を導入した。セガは一度、他社製の音声合成システムを導入したが、クオリティが低く、より自然な音声を出せるシステムを探していて、AIトークに出会ったという。
気象庁は、航空予報総合監視報知ツールにAIトークを使っている。気象庁はこの報知ツールを使い、気象情報をJALやANAなどの航空会社や空港の管制塔などに提供している。
具体的には、飛行場の風速や雲の高さが変化したときに、音声で「〇〇空港で、風速が基準に達しました」と知らせる。最終的には飛行中のパイロットもこの音声情報を耳にすることになる。
飛行中のパイロットは前方の景色や計器類を凝視しなければならないので、外部からの情報は文字データではなく音声データで受け取ったほうが都合がよい。ただ音声データは音がクリアでないと確認しづらいという欠点があった。
ところがAIトークの音声が明確かつ確実だったことから、気象庁に採用された。
まとめ -音声の再現の難しさ-
すでにCGを使わない映画のほうが珍しいのではないだろうか。映像の世界でのリアルさの追求は歴史が長い。
それに比べると、音声でのリアルさの追求は、ようやくスタートしたばかりといった印象だ。それくらい、人の声を再現するのは難しいのである。
しかしこれで、バーチャルな世界で映像も音声も簡単に再現できることになる。エンターテイメント分野での進歩は期待したいが、フェイクニュースや犯罪に使われることに警戒する必要が出てきそうだ。
<参考>
- Politicians discussing about Lyrebird(Sound Cloud)
https://soundcloud.com/user-535691776/dialog - 自然な音声作る「WaveNet」の衝撃 なぜ機械は人と話せるようになったのか(名古屋大学大学院情報学研究科教授、戸田智基)
http://www.itmedia.co.jp/news/articles/1803/27/news053.html - グーグルの「Tacotron2」が人間の声を再現、精度は「ほぼ人間」(Forbes)
https://forbesjapan.com/articles/detail/22817?n=1&e=19244 - Googleが音声合成を機械学習で訓練する方法Tacotron 2を発表、システムの調教が楽になる(TC)
https://jp.techcrunch.com/2017/12/20/2017-12-19-googles-tacotron-2-simplifies-the-process-of-teaching-an-ai-to-speak/ - 音声品質評価法(NTT)
http://www.ntt.co.jp/qos/technology/sound/02.html - 株式会社エーアイ
https://www.ai-j.jp/company/profile/outline/ - 音声合成エンジン AITalk®とは?(エーアイ)
https://www.ai-j.jp/about/ - 音声合成デモ(エーアイ)
https://www.ai-j.jp/demonstration/ - 導入事例、株式会社セガ・インタラクティブ(エーアイ)
https://www.ai-j.jp/client/voice7/ - 導入事例、気象庁(エーアイ)
https://www.ai-j.jp/client/voice19/
役にたったらいいね!
してください
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。






