京都大学の河原達也教授は、AI(人工知能)分野の「音声」領域の第一人者だ。
AIと音声の関係は、ドラえもんを考えると理解しやすい。ロボットのドラえもんは、のび太と自然な会話をするが、この機能を現代的に説明すると「ドラえもんには音声メディア処理が搭載されているから」となる。
河原教授の研究内容をベースにしながら、音声メディア研究の今を紹介する。(肩書は2019年9月現在)

河原達也教授
河原氏の肩書は、京都大学情報学研究科教授。
河原教授は京大大学院修士課程を修了したのち、アメリカのベル研究所などを経て2003年に現職。IEEEからFellowの称号を授与され、音声コミュニケーションの国際学会(ISCA)の理事を務めるなど、音声情報処理の我が国を代表する研究者である。
河原教授の「発明品」で有名なのが、国会の会議録を作成するための「自動音声認識システム」だ。政治家たちの発言を速記者が手書きで文字にしていたが、それをほぼ自動化した。
河原教授は、素人でも理解できるように「音声メディア分野の紹介」という1,200字ほど短い解説文を執筆している。
この記事はこの文章をベースにしている。
人は機械にどのような音声能力を持たせたいのか
AIや音声メディアの研究をしている人たちは、次のような音声能力を機械に持たせたいと考えている。
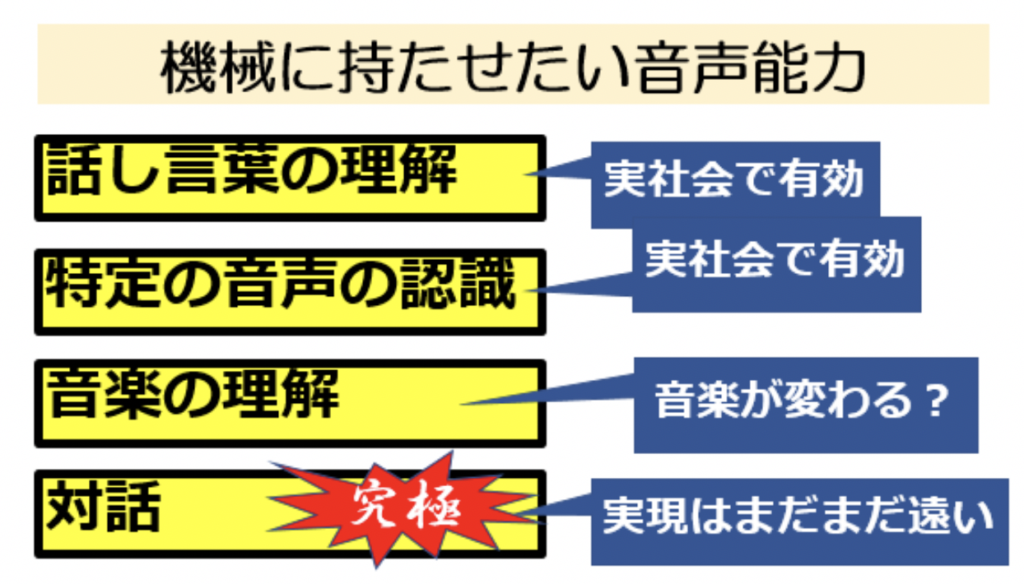
「音声メディア分野の紹介」を読む前に、これらの音声能力にどのような意味や価値があるのか考えてみる。
話し言葉を理解する音声能力は実社会で有効だ。
例えば、国会などでの議事録の作成。議事録は、立法機関や行政機関で議論されていることを国民が知るための重要な資料になる。
また企業であれば、役員会やプロジェクトチームの会議で打ち合わせしたことを文字に変換できれば、経営者の考えや現在進行中のプロジェクトを全社員に周知できる。
他人の話し言葉を文字にすることはとても手間がかかる。話し言葉から意味を抽出し、意味のある文章をつくることは人しかできなかった。そのため、話し言葉が文字化される機会はとても少なかった。しかし話し言葉を理解する音声メディア処理が開発されれば、あらゆる音声会話を容易に閲覧・検索できるようになる。
特定の音声の選別
人が集中力を発揮すれば、パソコンでユーチューブを流しながらでも、テレビのニュース番組の報道内容を理解することができる。人の聴力は、複数の音のなかから1つの音だけを抜き出すことができるからだ。
しかし機械に複数の音を聞かせると混合音として認識されてしまう。その混合音を、もつれた糸をほどく作業をするのが、特定の音声を認識する音声メディアだ。これを開発できれば、世界の音のカオスから情報を含む音だけを抽出することができるようになる。
音楽の理解
音楽を理解する音声能力は、特定の音声を認識するシステムと似ているが、こちらは音楽に特化したものである。
例えば、歌手がピアノの伴奏で歌ったとする。歌手は見事に歌い上げたが、ピアノ伴奏はところどころ失敗したとしよう。従来の録音技術では、歌手には申し訳ないが、もう一度ピアノ伴奏つきで歌ってもらうしかない。
しかし音楽を理解するシステムが開発されれば、歌手の歌声だけ抽出することができる。それができれば、歌手には帰宅してもらって、ピアノの伴奏だけを録音し直すことができる。
また、歌声だけ、ピアノ伴奏だけを抽出できれば、音楽の再編集も可能になる。
音声対話システム
音声メディア研究の究極は、対話である。
例えば、ホテルのロビーにおける、客とコンシェルジュの対話を考えてみる。コンシェルジュはホテル内のことだけでなく、ホテル周辺の観光や交通機関の情報などにも答えなければならない。
客から質問や要望を受けたコンシェルジュは、客の意図や嗜好を対話のなかで明確にしていく必要がある。例えば客のなかには「なんとなく食事をしてそれから観光地を巡りたいんだけど、どこがいいかな」といったように、明確な目標を持っていない人もいる。
河原教授たちは「情報コンシェルジュ」というコンセプトの研究を行っている。ユーザーが「なんとなく」喋っていることに対し、音声対話システムのほうで質問をして必要な情報を特定していく。
この音声対話システムが完成すれば、料理サポート音声メディアや法律支援音声メディアを構築することができる。
これからの音声対話システムは、ユーザーの質問に答えるだけでなく、能動的に情報を提示することが求められる。
そしてこうした音声対話システムが完成すると、ドラえもんの領域にかなり近づくことができる。
4つの領域で進化する音声メディア
それでは河原教授の「音声メディア分野の紹介」をみていこう。
河原教授によると、今の音声メディア研究は「話し言葉の音声認識」「音環境理解」「音楽情報処理」「ロボットとの音声対話・インタラクション」の4つの領域にわかれているという。
先ほど確認した「機械に持たせたい音声能力」との対比はこのようになる。
・話し言葉の音声認識→話し言葉の音声認識・理解
・音環境理解→特定の音声の選別
・音楽情報処理→音楽の理解
・ロボットとの音声対話・インタラクション→対話
話し言葉の音声認識の研究の今
話し言葉の音声認識が難しいのは、文法に則っていないからだ。しかも日本語は同音異義語が多く、主語や述語もたびたび省略される。
それでも話し言葉を理解できるのは、聞き手に予備知識や推測力があるからだ。
それで、文法を逸脱した主語なし述語なしの音声を文字にして第三者に読ませると、正確な意味が伝わらない。
話し言葉の音声認識の研究では、話し言葉音声を自動で認識して、情報や文章構造を抽出しようとしている。機械に「この話者は、きっとこういうことを言いたいのだろう」と考えさせようとしているのである。この研究分野では、話し言葉から要約文を作成する研究も進んでいる。
河原教授の研究室では、講演・講義や会議のような実世界の話し言葉音声を自動認識し、情報・構造を抽出し、さらに講演録・会議録や字幕・要約などを生成する方法についての研究を行っており、国会の会議録作成支援、大学の講義や学会の講演の字幕付与支援を行うシステムを構築している。
音環境理解の研究の今
日常生活のなかは、音であふれかえっている。
そこで音声メディアの研究者たちは、音のカオスのなかから意味のある音、つまり重要な情報を含む音声だけを取り出すために「マルチモーダルセンシング」と「統計的な音響信号処理」という2つの技術を開発した。
この特殊技術によって、抽出すべき音源を推定したり、複数の音源をひとつひとつの音源に分離したり、雑音を排除することができるようになった。
河原教授の研究室では、複数の話者が存在したり、音声以外に様々な音が存在している環境の認識・理解を、マルチモーダルセンシングと統計的な音響信号処理に基づいて行っており、音源推定・音源分離・雑音抑圧などの処理を研究し、人込みの中の会話に適用している。
音楽情報処理の研究の今
複数の歌声と複数の楽器のメロディーからなる音源から、ひとつひとつの音を分離するのが、音楽情報処理である。
歌声や楽器の音には、音楽音響信号が含まれている。この信号を頼りに音源を分離するのである。分離した音は再編集することもできる。
カオス状態の音源であっても、ここまで細分化できれば、あとはAIで音楽の調、コード、リズムを解析できるようになる。
音楽情報処理の研究では、特定の人に推薦できる音楽を探す技術や、作曲支援システムや演奏支援システムの開発も進んでいる。
ロボットとの音声対話・インタラクションの研究の今
アトムやドラえもんの会話能力はもはや夢物語ではなく、音声メディア研究者やAI研究者たちの目標になっている。
音声対話研究では、言語情報だけでなく非言語情報も取り入れようとしている。これによりロボットはより人間に近い振る舞いができ、インタラクションも可能になる。
インタラクションとは「相互作用」という意味で、ロボット分野の専門用語である。人がアクションを起こしたときに、ロボットがそのアクションに応じたリアクションを取ることをいう。
音声対話でのインタラクションが実現すれば、独居のお年寄りの話し相手になるロボットをつくることができる。
お年寄りの発言の意味を理解できるAIと組み合わせれば、お年寄りの心理を推測することもできるようになるだろう。
河原教授の研究室では、大阪大学・ATRと共同で開発しているアンドロイドERICAで、傾聴や面接などの自然な対話を行うシステムを開発している。
まとめ~人の生活を豊かにする
AI開発のなかで音声メディアの研究に注目が集まっているのは、音声がとても自然な情報伝達ツールだからだ。
河原教授が開発しているもののひとつに、傾聴や面接などの自然な対話を行うシステムがある。河原教授はこれを、高齢者や一人暮らしの人のための、長く会話できるロボットに応用したいと考えている。
音声メディア処理は、人の生活を豊かにする技術である。
<参考>
- 「音声メディア分野の紹介」(京都大学情報学研究科河原研究室)
http://sap.ist.i.kyoto-u.ac.jp/ - 音声対話システムの進化と淘汰(河原達也)
http://winnie.kuis.kyoto-u.ac.jp/~kawahara/paper/KAW-slud13-2.pdf
役にたったらいいね!
してください
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。






