京都大学情報学研究科知能情報学専攻の山本章博教授はAI(人工知能)研究の第一人者の1人である。
AIは最近ようやく、一般の人にとって、だいぶ親しみやすい技術になってきた。監視カメラに使われたり、スーパーのレジに使われたり、事務仕事に導入されたりしている。
かつて世の中に「ネットやらITやら」が出始めたころ、人々は戸惑いながらも徐々に慣れていった。AIも今、そのような状況にあるようだ。「もう少しでAIは一般の人たちのものになる」そのように感じている人も多いだろう。
ところが、山本氏の研究は、一般の人レベルのAI知識では、すぐには理解できないかもしれない。例えば山本氏は、自身の研究室のテーマを、次のように説明している。
・人間の高次推論機構の性質を解明する
・人間の高次推論機構を用いて、与えられたデータから適切な情報を取得するための計算機構とソフトウェアを構築する
・データ集合から知識発見を行なう
AIは、ネットやITのように、一般の人々の生活を快適にするものである。そうであれば、山本氏の研究も、一般の人々の生活に役立つはずである。
そこで、山本氏の「AIの話」を読み解いてみよう。

京大・山本研究室はデータを研究している
京大・山本研究室では、機械学習や知識発見の対象となるデータを、離散構造データとして扱うことをテーマにしている。
機械学習はAIの一種である。知識発見とは、人間にとって有用な知識を取り出す仕組みである。
要するに山本研究室は、AIやコンピュータをより賢く動かすために、データをどのように取り扱うか、という研究をしているわけである。
「これ」を解明してみよう
山本氏は、自身の研究分野について、次のように説明している。
これを題材にして、山本氏がしていることの「一端」を探っていこう。
| 山本研究室では、離散構造データからの知識発見や機械学習のアルゴリズムを構成しようとしている。 画像や音声は、実世界ではアナログ量として存在している。それらをコンピュータで処理するときには、アナログ量を取り込む。 コンピュータに取り込まれた画像データや音声データのことを、数学用語である「連続」を借りて「連続データ」という。現在注目されている機械学習はもともと画像認識用で、人間の網膜から脳内に至る神経回路をお手本にして設計されているので、画像データという連続データ用である。 一方で、実世界には「離散構造データ」が多く存在する。 例えば、スーパーで買い物をしたときに、一つの買い物籠に入っている商品に印刷されているバーコードの集合は離散構造データである。 インターネット上でのホームページのIPアドレスとそのページから張られているリンクの先のホームページの対も離散構造データである。ホームページに書かれている文章も離散構造データである。 離散構造データから知識発見や機械学習を行なうには、適当な属性を大量に用意して、データをベクトル化するという前処理が必要になる。 その前処理によって連続データができるので、連続データ機械学習アルゴリズムにかけるのである。 しかし、連続データと離散構造データは素性がまったく違っているため、この手法はどこかで「歪み」が生じる可能性がある。 この歪みは、正確な知識発見や正確な機械学習を阻害する可能性がある。 そこで山本研究室では、「離散構造データにはそれに適した数理があって、離散構造データからの知識発見・機械学習はその数理を用いて構成されるべきである」という信念のもとに研究を行っている。離散構造データに適した数理のことを「離散最適化数理」という。 機械学習は離散最適化数理と密接に関連しており、最適化数理は、計算量理論という計算の本質を明らかにする学術分野と関係する。 ただ、その計算量理論では、数々の「難問」が提示され、あるものは解決され、あるものは未解決のままである。 これをどのように解決していけばよいのか。 すべてを論証によって解決する数学と違って、山本研究室が関わっているコンピュータサイエンスでは「アルゴリズムを改良することによる実質的な解決」を用いる。 知識発見・機械学習の視点からそのような解法を求めるのも山本研究室のテーマである。 |
この説明には、専門用語が多く含まれているので、一般の人の理解を助けるために概念図をつくってみた。
山本氏は知識発見と機械学習の両方を扱っているが、ここでは話をシンプルにするために、機械学習だけに絞ってみた。
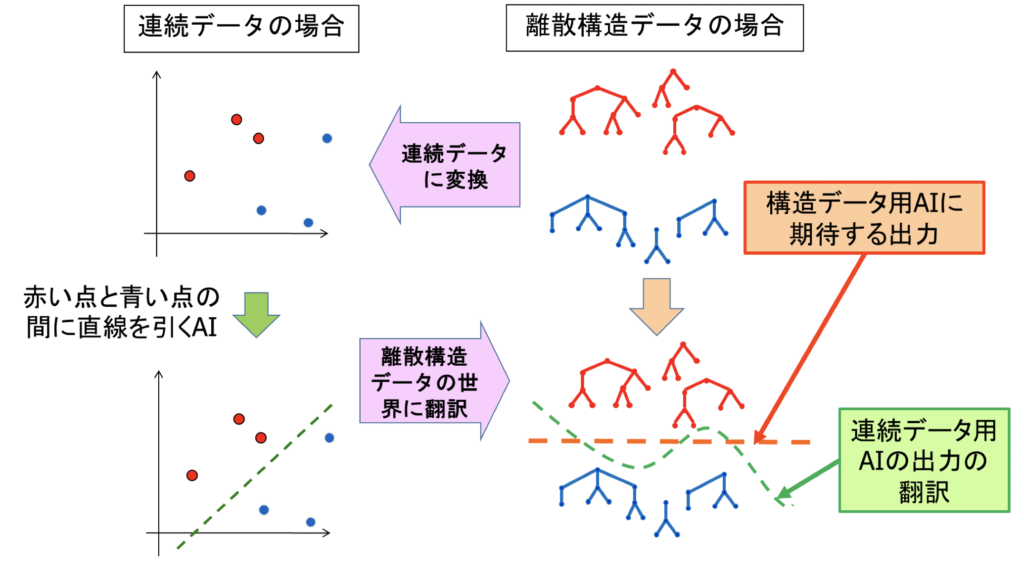
連続データとは、離散構造データとは
先ほど作成した「離散構造データを機械学習する」の概念図を、今度は文章に戻してみよう。
ここでは「機械学習」という単語を、世間でなじみのある「AI」に置き換えてみた。
現在、注目されているAIは、もともと画像という連続データ用である。
しかし、世の中には「連続データ」だけではなく「離散構造データ」もあふれている。
したがって無理矢理「離散構造データ」を「連続データ」に加工してしまうと、歪みが生じて、AIが正しい判断を出せなくなる可能性がある。
だから山本研究室では、「離散構造データ」を「離散構造データ」のままAIで使えるようにできないか、という研究している。
ここまでくると、山本氏たちが何をしようとしているのかが、少しみえてきた。
しかし、一般の人には、そもそも「連続データ」と「離散構造データ」がよくわからないのではないだろうか。
最適化数理とアルゴリズムでなんとかする
それではいよいよ、山本氏が「いわんとしていること」に迫っていこう。
連続データと離散構造データ
連続データは、「隙間ができないデータ」のことだ。例えば「測定値」は連続データである。
Aさんは身長175センチで、Bさんは身長176センチだったとする。このとき、身長の低い順に並べると、「Aさん→Bさん」の順になる。
そこに、身長175.5センチのCさんが加わると、「Aさん→Cさん→Bさん」の順になる。
さらにそこに身長175.51センチのDさんが加わると、「Aさん→Cさん→Dさん→Bさん」の順になる。
このように「身長」は連続しているので、連続データと呼ばれる。
ひとつの物体をデジカメで撮るとき、デジカメの画素数が多ければ多いほど正確に忠実に撮影できる。画像はアナログ量なので、画素と隣の画素の間に画素が割り込むことができるからである。画像データは連続データということになる。
これに対して「離散」とは「とびとびの値を持つ」ということだ。例えば、集合している人の人数を数えるとき、「1人、2人、3人…」と数える。「1人、1.3人、1.5人、2人、2.1人、2.8人、3人…」とは数えない。
つまり「1人」と「2人」は連続してなく「離散している」といえる。「そこに1人いる」状態であれば、0.7人でも1.5人でもなく「1人」だからだ。「そこに2人いる」状態は「2人」以外にない。
このように、身長の計測データ(連続データ)と、一定区域内の人数のデータ(離散データ)は、同じ数字でも性質がまったく異なる。
ここまで理解できると、山本氏たちが何をしようとしているのかが、また少し見えてくる。
直感的に「今流行のAIは離散構造データの取り扱いが苦手だ」ということはわかる。AIが網膜や神経をお手本にしているからだ。しかし,もともとコンピュータは「0か1か」という離散したデータしか扱うことができない。
だから離散構造データを連続データに加工して「あげる」ことは、コンピュータにとっては「二度手間」「回り道」のはずだ。
しかし確かに山本氏の指摘するとおり、世の中には離散構造データがあふれている。離散構造データを無理矢理、連続データに変えると「歪み」が発生することも直感的に理解できる。
したがって、世の中に存在する離散構造データを、離散構造データのまま使えるAIができれば、歪みのない結果が得られる。これが山本氏のゴールのひとつだ。
ところが、ここでスタート地点に戻ってしまう。そう、「連続データにしないと、流行中のAIで使えない」という問題だ。
さらなる未知の領域へ
山本氏は、どのように「連続データにしないと流行中のAIで使えない」という問題を克服して、離散構造データのまま使えるAIを作ろうとしているのだろうか。
その答えは、山本氏の話のなかにある。研究分野の説明内容の後半部分を再掲する。
| 離散構造データに適した数理のことを「離散最適化数理」という。 機械学習は最適化数理と密接に関連しており、最適化数理は、計算量理論という計算の本質を明らかにする学術分野と関係する。ただ、その計算量理論では、数々の「難問」が提示され、あるものは解決され、あるものは未解決のままである。 これをどのように解決していけばよいのか。 すべてを論証によって解決する数学と違って、山本研究室が関わっているコンピュータサイエンスでは「アルゴリズムを改良することによる実質的な解決」を用いる。 知識発見・機械学習の視点からそのような解法を求めるのも山本研究室のテーマである。 |
山本氏は、この課題を、離散最適化数理を使って解決しようとしている。
ところがこの離散最適化数理にも難問がある。その難問は、アルゴリズムを改良して対応しようとしている。
山本氏はさらなる未知の世界に行こうとしている。
まとめ~基礎研究に期待
抗がん剤などの新薬の開発には基礎研究と臨床研究があるが、脚光を浴びやすいのは臨床研究だ。なぜなら、臨床研究が完了すると「画期的な新薬ができた」と評価されるからだ。
しかし、新薬開発では基礎研究が欠かせない。基礎研究あっての臨床研究である。
AI開発の現場でも、新薬開発と似た構造になっている。経済新聞などのマスコミで紹介されるAIは臨床研究の結果である。そこでは「AIがまた画期的な仕事を成し遂げた」と報じられる。
しかし山本氏たちが行なっているAIの基礎研究があればこそ、AIは一般の人でも使いこなせる技術になったといえる。
「山本氏の話」を本当に理解することは簡単ではない。しかし山本氏たちが「何をしようとしているのか」を知っておくことは、これからのAI時代を生き抜く必要がある人たちは知っておいたほうがよいだろう。
<参考>
主な研究テーマ(山本研究室)
http://www.iip.ist.i.kyoto-u.ac.jp/page-research
山本研究室(山本研究室)
http://www.iip.ist.i.kyoto-u.ac.jp/
山本章博(KAKEN)
https://nrid.nii.ac.jp/ja/nrid/1000030230535/
山本章博プロフィール(京都大学 大学院 情報学研究科 知能情報学専攻)
http://www.iip.ist.i.kyoto-u.ac.jp/member/akihiro/
離散データと連続データ
http://www5e.biglobe.ne.jp/~emm386/2016/frequency/scale03.html
データの種類(なるほど統計学園高等部)
https://www.stat.go.jp/koukou/howto/process/proc4_1_1.html
知識発見(weblio)
https://www.weblio.jp/content/%E7%9F%A5%E8%AD%98%E7%99%BA%E8%A6%8B
役にたったらいいね!
してください
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。






