マサチューセッツ工科大学(MIT)は、米国を代表する大学の一つである。その中でも人工知能(AI)研究は歴史も古く、研究レベルの高さでは米国1,2を争っている。そんなMITのAI研究のうち、ドラマの映像から次の動作をAIに予測させることに成功した事例を紹介しよう。

MITにおけるコンピュータビジョンの実験事例
ホームドラマから得られるAIの研究成果
ホームドラマのワンシーン。家に男性の客が訪問し、それを女性が出迎える。そのあとに起きることは何だろうか。ハグ?それともキス?
われわれ人間ならば、2人が接近したときに次に何が起きるのかをおおよそ想定できる。ところが、これを機械に実行させるのは容易ではない。われわれは視覚的な判断だけで、その後の2人の行動を予測しない。ドラマ演出の常套手段や、われわれの慣習といった背景情報を、予測のために援用するからだ。他方機械の場合、認識した画像データによってのみ処理される。ドラマの映像自体は2次元だが、実際は3次元で起きている事象を2次元に変換している。変換された2次元情報を、機械は処理する。このような画像処理に関する一連の技術が、コンピュータビジョンと呼ばれる分野だ。
このコンピュータビジョンにおいて、AIが活用される。AIがパターン認識に強みを発揮することを理解していれば、AIが動画の認識に活用されることは容易に想像されよう。この動画認識で画期的な成果を出したのが、CSAILである。AIを活用し、従来のコンピュータビジョンの技術よりも高確率で、将来の動作を動画から予測することに成功したのだ。
MITの長いAI研究の歴史
CSAIL(Computer Science And Intelligence Laboratory)は、MIT内の人工知能に関する研究機関である。人工知能研究というと、GoogleやAmazonといった企業の名前を思い浮かべるかもしれない。GoogleがAIに投資した額は、スタートアップ企業の買収した額を含めて推定で3.9兆円程度である。投資額2位のAmazonでも、推定で8,710億円程度というのだから、Googleの規模は群を抜いている。
大学の研究機関の強みは、学術的な探求にある。米国が産学連携を推進しているとはいえ、目先の利潤にとらわれることなく100年先を見据えた研究を行なえるのは大きい。MITはカーネギーメロン大学と並び、アメリカでは最大級の人工知能研究機関として知られる。大学ランキングで名高いUSニューズ&ワールド・リポート誌が発表する2018年のAI分野でのランキングでは、MITはカーネギーメロン大学に続いて第2位につける。
CSAILの前身であるMAPプロジェクト(the Project of Mathematics and Computation)と呼ばれるコンピュータサイエンスの研究機関が設立されたのが、1963年である。AI研究の行なう人工知能研究所(1959年創設)もMAPプロジェクトの中に含まれる。人工知能の父と呼ばれ、ニューラルネットワーク理論の基礎を築いたマービン=ミンスキー博士も、MITの人工知能研究所の創設者のひとりだ。このことからも、MITの果たした人工知能への貢献は計り知れない。
とはいえ、企業のバックアップなしに人工知能の研究は成立しえない。ご存知の通り、アルファ碁と呼ばれる人工知能を開発したのはGoogleが買収したディープマインド社だ。Googleは世界中から人工知能の研究者を集め研究させるのだから、トップレベルの人工知能の研究機関であることに異論はないだろう。事実Googleもまた、MITの人工知能研究に一役を買っている。本研究の主要メンバーであるMITのカール=フォンドリク(当時学生)は、Googleの研究支援を受けていた。ちなみに現在は、Googleの研究員をしながらコロンビア大学の助教授(Assistant Professor)に就いている。このほかにも米国半導体メーカーでありAI分野で存在感を示すNVIDIAも本研究を支援する。
従来のコンピュータビジョンの限界
従来のコンピュータビジョンのアプローチは2種類ある。1つめは、個々のピクセルを見て、その知識に基づいてビクセルごとに未来の画像を作り出すというものだ。ところが、アルゴリズムがほとんどなく、非常に難しい。2つめは、あらかじめ人間がシーンごとにラベル付けを行なう方法だ。しかし、大規模な画像処理を行なうのは実用的ではない。
本実験に関するAIのメカニズム
AIがコンピュータビジョンの未来を切り開く
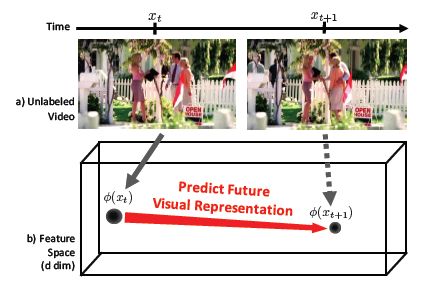
(出典:https://www.csee.umbc.edu/~hpirsiav/papers/prediction_cvpr16.pdf)
本実験でドラマ内の動作の予測に用いるのは、”visual representation”と呼ばれる、画像から特徴を集約させた情報である。図のように、動画が再生されるにしたがって、visual representationがコマ送りのように遷移するというイメージだ。
visual representationを予測するのに一役買うのが、ディープラーニングだ。入力層・中間層・出力層の3種類の階層から成り、大量のデータを入力層に与える。中間層で最適な出力を得るために、大量のデータを中間層で学習させる。出力層からは、学習によって得られた回答が出力される。大まかな流れはこの通りだが、実際にはAlexNetやGoogleNetといった画像認識に特化した畳み込みニューラルネットワーク(CNN)が用いられる。AlexNetは9層、GoogleNetは22層だから、その複雑さは容易に想像できるだろう。
本実験では、Youtubeから600時間もの動画を入力として利用する。動画の内容は、『ジ・オフィス(The Office)』や『デスパレートな妻たち(Desperate Housewives)』といった米国ドラマだ。このドラマから、5秒後の動作を予測させる。動画にキャプションをつけるといった「ラベルづけ」を、人間は一切行っていない。必要なのは、大量に集めたビッグデータ(この場合は動画)だけである。
学習を行った後に予測するのは、ピクセルやラベル付けされたカテゴリーではなく、visual representationそのものである。ピクセルごとに将来を予測する必要もないし、カテゴリーを人間があらかじめ用意する必要もない。動画の情報がvisual representationに集約しているわけだ。
(出典:https://www.csee.umbc.edu/~hpirsiav/papers/prediction_cvpr16.pdf)
visual representationを予測するといっても、1つのvisual representationを出力するのではなく、将来起こりそうなシーンを複数まとめて出力する点も興味深い。図のように、各動作がどのくらいの頻度で生じるのかを予測する。未来は不確実なので、複数の可能性を想定するというのは理にかなった考えだろう。本実験では、何種類の未来を想定するのかベストかを、実験で比較している。3通りの未来を想定するモデルだと高い確率で未来の動作を予測できるという実験結果が得られている。
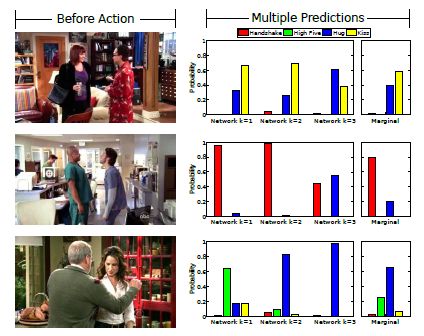
動作の予測確率は43%

(出典:https://www.csee.umbc.edu/~hpirsiav/papers/prediction_cvpr16.pdf)
今回の実験では、2種類の予測を行なっているという。1つめは、ハグや握手といった動作の予測するもの。2つめは、数秒後に電子レンジの中から現れる物体は何かといった、対象の予測である。前者に関しては、5秒後に起きる動作を43%の確率で予測できたという。
図3を確認していただきたい。一番左の列が、動作を開始する前の映像だ。この数秒後に起きる動作を予測する。機械学習によって得られた予測動作は、左端の画像の下に記された通りである。右側に表示された動作結果を照合させるとわかるように、ハグやキス、ハイタッチ(high five)といった動作を見事的中させている。従来の方法では36%の的中率だから、一歩前進であろう。ただし、第三者が突然割ってくるといった突発的な動作が生じた場合には、誤認識することも報告されている。
他方後者に関しては、正答率は11%とずっと低い。人間が71%の確率で、扉から出てくる対象を予測できるのと較べると雲泥の差である。それでも、開発者のフォンドリクは、動画についての複雑な未来予測もまもなく可能だという見通しをつけている。
今後の課題と展望
MITの実験からも明らかなように、Googleのような人工知能の研究に莫大な予算を投入できる機関でなくても、画期的な研究成果が出すことは可能だ。実際、MITのCSAILはこのほかにも、AIにグーグルマップから道路を抽出することに成功している。ご存知のように、Googleは莫大な時間と予算をかけて、現地に人を派遣し道路を調査させている。ところが、Googleでさえ実施していなかった道路図の作成を大学の研究機関がやってのけた。
このことからも示唆されるように、人工知能研究はアイディア次第で画期的な成果が得られる余地がある。今回のドラマの例で言うと、単なるドラマのワンシーンを予測することにとどまらない。フォンドリクは、セキュリティシステムに応用できるのではとインタビューに答えている。誰かが高いところから落ちたり、けがをしたりすることを事前に予測できれば、警報を鳴らすなど対策も取れよう。
MITのAI事例は人工知能研究に入り込める余地を残した好例
ご覧のように、MITの人工知能研究の歴史は長く、最先端の学術研究を行っている。たしかにGoogleやAmazonといった莫大な予算を投入できる企業と較べると、規模は小さい。しかし産学連携を上手く活用し、Googleでも研究できなかった分野を発掘していることからも、人工知能研究にはまだまだ隙間に入る余地があるかもしれない。
<参考>
- Teaching machines to predict the future (MIT News)
http://news.mit.edu/2016/teaching-machines-to-predict-the-future-0621 - MIT’s new A.I. could help map the roads Google hasn’t gotten to yet (Digital Trends)
https://www.digitaltrends.com/cool-tech/mit-mapping-roadways-tech/ - The 10 tech companies that have invested the most money in AI (Tech Republic)
https://www.techrepublic.com/article/the-10-tech-companies-that-have-invested-the-most-money-in-ai/ - Mission & History
https://www.csail.mit.edu/about/mission-history - Artificial Intelligence (U.S. News)
https://www.usnews.com/best-graduate-schools/top-science-schools/artificial-intelligence-rankings - Carl Vondrick
http://carlvondrick.com/ - 600時間分のドラマを観た人工知能による「人間行動の予測」の精度 (Wired)
https://wired.jp/2016/06/24/algorithm-tv-program/ - 胃が痛む「MITの競争生活」で学んだこと(東洋経済オンライン)
https://toyokeizai.net/articles/-/13005 - ディープラーニングの進歩を振り返る(マイナビニュース)
https://news.mynavi.jp/article/deeplearning-3/ - 「Anticipating Visual Representations from Unlabeled Video」(Carl Vondrick, Hamed Pirsiavash, Antonio Torralba)
- 『3次元コンピュータビジョン計算ハンドブック』(金谷健一、菅谷保之、金澤靖著)
- 『実践 コンピュータビジョン』 (Jan Erik Solem 著)
役にたったらいいね!
してください
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。






