IBMが、音声認識という技術の開発に力を入れている。音声認識は人の発した音声が文字になってパソコン画面に現れる技術である。例えば会議の発言内容をすぐに紙の資料におこすことができる。
それだけでも十分便利であるが、音声認識には別の使命がある。それはAI(人工知能)を格段に便利にすることだ。

IBMの立ち位置とAI
音声認識はいわば「文字起こし」だ。例えば速記者は人の話す言葉を素早く文字にすることができるが、この技術をコンピュータで再現しようというわけだ。
ただ、IBMが音声認識に注力しているのは、もうひとつの有用性があるからだ。それは「コンピュータとの会話」だ。
音声認識できないパソコンに人が話しかけても何も反応しないのは、コンピュータは音声を理解できないからだ。しかし音声認識技術によって人の音声をデジタルデータに変換できれば、コンピュータは人の発した言葉を理解できるようになる。これが「コンピュータが人の言葉を理解する」ことの第一歩となる。
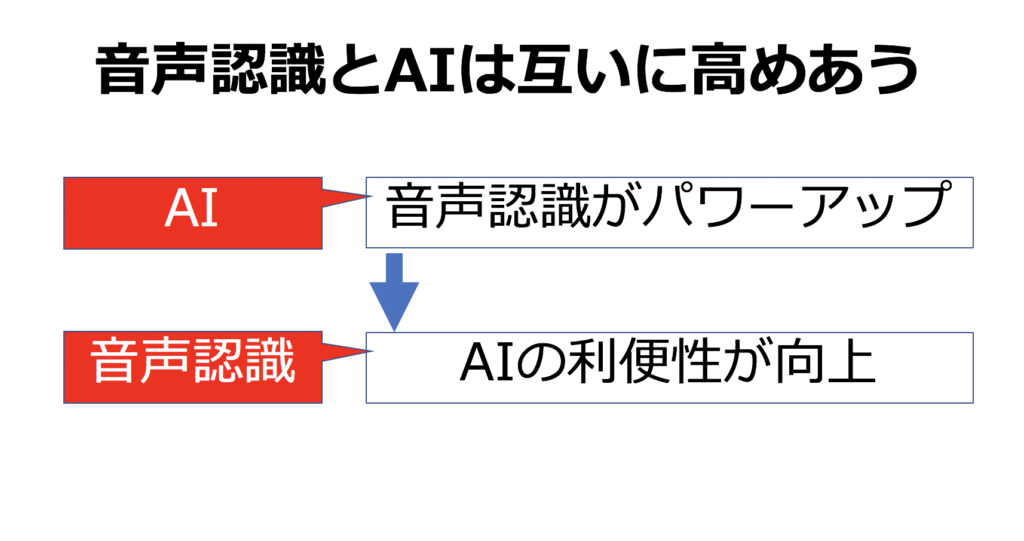
音声認識とAIは相互に高め合う関係にある。音声認識の能力は、AIによって格段に向上する。そして音声認識の技術が確立すると、AIの利便性が格段に向上する。
IBMは世界に冠たるIT企業であるが、IT業界はいまGAFA(ガーファ)の4社が先頭集団を構成している。IBMはそこに入ることができていない。
GAFAとは、グーグル、アップル、フェイスブック、アマゾンのことである。
ヤフージャパンが公表している2018年9月時点での米国株時価総額ランキングでは、1位アップル、2位アマゾン、3位マクロソフト、4位アリババ、5位グーグル、6位フェイスブックとなっている。そしてIBMは55位だ。
だからいってIBMの企業価値が低いといっているわけでもないし、同社の技術が陳腐化しているわけでもない。IBMのIT技術は、多くの企業にとって欠かすことができないものだ。ただGAFAに比べて存在感が薄いのは事実だ。
そのようなIBMにあって、AIは起死回生の一手となりうる。
IBMのAIのブランド名は「ワトソン(Watson)」という。IBMはワトソンを使って、顧客企業にソリューションを提供する。
例えばワトソンは、石油掘削用の機械があとどれくらいで故障するか、運送会社が大量に保有しているトラックの買い替え時期などを予測する。
さらにIBMは、自動車業界にも目を向けている。自動運転車やライドシェア、コネクテッドカーなど、ITが必要とされるシーンが多いからだ。IBMはここでもワトソンを使ったソリューションビジネスを狙っている。
だからIBMは、音声認識技術に力を入れているのである。
音声認識技術を確立すれば、人によるAI搭載コンピュータへの指示が格段に楽になる。スマホの音声検索やスマートスピーカーなどの音声認識を使った商品はすでに市販されているが、まだ趣味レベル、エンターテイメントレベルにとどまっている。
IBMが想像する「音声認識+AI+コンピュータ」はそれよりもはるかに規模が大きく、世界中の産業の変革である。
いまのIBMの音声認識の実力
IBMの強力なライバルであるマイクロソフトは2016年に、NIST(米国立標準技術研究所)のベンチマークで、音声認識技術のワードエラーレートが5.9%に達したと発表した。
つまり、音声認識技術の単語誤り率を5.9%にまで減らすことができた、というわけだ。
そのときマイクロソフトは、自社の音声認識技術が「ヒューマンパリティに到達した」とコメントした。ヒューマンパリティ(human parity)は「人格」や「人間と同程度」という意味である。人間並みに人の音声を理解できるコンピュータをつくった、と言ったのである。
単語誤り率とは、音声を聞いたAIがどれくらい正確に文字起こしできるかを示す指標だ。単語誤り率の数値が小さいほど音声認識の能力が高いことを示す。
マイクロソフトの5.9%の前は、IBMの6.9%が世界最高だった。
しかしIBMの幹部は、マイクロソフトの「ヒューマンパリティに達した」というコメントに対し、「我々IT企業は、まだシャンパンを開けて祝福する段階ではない」と述べた。つまり単語誤り率5.9%では、「まだまだだ」と言ったのである。
そしてIBMは2017年3月に単語誤り率5.5%を達成し世界一に返り咲いた。
それでもIBMは音声認識開発の手を緩めるつもりはなく、コンピュータが真のヒューマンパリティ(人間と同程度)を獲得するには、5.1%以下にまで精度を高める必要があると考えている。
コールセンターですでに使われている
IBMワトソンの音声認識はすでにユーザー企業で実用化されている。例えばコールセンターを持つ企業では、顧客からの問い合わせ電話の音声を、オペレーター(人)と音声認識に聴かせている。オペレーターが顧客と会話しているとき、音声認識は音声を文字化するとともに、例えば顧客が製品の固有名詞を出せば、その製品の説明書をオペレーターに示すことができる。オペレーターはあたかも説明書の内容を暗記しているかのようにスラスラと解説することができる。
また現行のIBMの音声認識は、人が10分間話し続けても、それを文字化することができる。
IBMは「音声認識によってコンピュータと会話できる」と話している。
そもそも音声認識とは
IBMの音声技術には、「スピーチtoテキスト」と「テキストtoスピーチ」の2種類がある。「音声を文字に変える技術」と「文字を音声に変える技術」のことだ。
両者の基本構造は同じなので、スピーチtoテキストの概要を解説する。
人が「あ」を聞いた場合、それは「ア行の最初の文字」という意味を持つ。しかし自然界では「あ」は単なる音にすぎない。音としての「あ」と、ア行の最初の文字としての「あ」は、物理的には同じだが、文化的にはまったく異なる。
「ア行の最初の文字」としての「あ」のことを音素という。
コンピュータが「あ」を単なる音ではなく、音素であると認識するためには、まずは「あ」という音をデジタル化する必要がある。続いてデジタル化した情報を、スペクトル表現に変換する。そしてようやくコンピュータは、スペクトルの特徴量かから音素「あ」を特定するのである。
ちなみに特徴量とは、情報やデータの特徴を数値化したもののことである。
この流れをまとめるとこうなる。
・人が「あ」と発音
↓
・デジタル化情報に変換
↓
スペクトル表現に変換
↓
スペクトルの特徴量の特定
↓
コンピュータが「『あ』という音素」と認識
この流れのことを、音響モデルという。
ただ音響モデルでは、音素(例えば「あ」や「り」や「が」や「と」や「う」など)を特定するだけなので、これでは言語にならない。
言語にするには「『あ』と『り』と『が』と『と』と『う』をつなげると『ありがとう』になる」、ということをコンピュータに覚え込ませなければならない。
コンピュータが「『あ』と『り』と『が』と『と』と『う』が並んでいるということは、この話者は『ありがとう』と言っているんだな」と理解させるには、言語モデルをコンピュータに覚え込ませる必要がある。
以上のことをまとめるとこうなる。
・人が「あ」「り」「が」「と」「う」という音を発する
↓
・コンピュータが音響モデルを使って「あ」「り」「が」「と」「う」という音素を認識する
↓
・コンピュータが言語モデルを使って「ありがとう」という言葉であることを理解する
音響モデルと言語モデルの2つがあるから、音声認識ができるコンピュータは「あ」「り」「が」「と」「う」を「蟻蛾頭」と書かれずに「有難う」と書くことができる。
そしてIBMでは、音響モデルと言語モデルをつくる過程で、AIの基礎技術であるディープラーニング(深層学習)を使っている。AIで音声技術を鍛え上げているのだ。
スピーチtoテキスト、テキストtoスピーチの活用法は無限
音声技術の活用法としてはすでに、会議の発言を瞬時に議事録にしたり、コールセンターで顧客の声を文字化したりする事例を紹介した。
しかしIBMは、スピーチtoテキストとテキストtoスピーチの2つの音声認識技術の活用法は、企業のアイデア次第で無限に広がる、としている。
例えばロボットやコグニティブ家電(認知機能を搭載した家電)に音声技術を搭載すれば、人がロボットや家電と会話することができる。
また産業現場の作業員が、手を使うことができなかったり視線を動かしたくなかったりするときに、音声で機械に指示を出せると便利だ。
例えば搬送ロボットに音声認識機能を搭載すれば、広大な商品倉庫のなかで作業員が商品をピッキングするときに、商品名を言うだけで済む。棚の高い場所まで作業員が行く必要がなくなる。
また自動車に音声認識機能を搭載すれば、ドライバーは前方を見て運転に集中しながら、声かけだけで音楽をかけたりエアコンの温度を調整したり窓を開けたりすることができる。

まとめ~IT名門企業の本気度
IBMよりGAFAのほうが注目されるのは仕方がない部分もある。GAFAが展開するSNSやeコマースやスマホは生活に密着しているため、人々のその4社への親密度も増す。一方のIBMはBtoBビジネスが中心なので、消費者にはIBMのビジネスが見えづらい。それが株価にも影響を与え、IBMの時価総額はGAFAよりかなり劣る。
しかしIBMはAIや音声認識技術でビジネス界に革命を起こそうとしている。AIが当たり前の時代になれば、再びIT名門企業の名が日常生活に溶け込むことになるのかもしれない。
<参考>
- IBM、音声認識の誤り率でMSの記録更新–「人と同等」レベルには未達と判断(ZDNet Japan)
https://japan.zdnet.com/article/35098039/ - Speech to Text (音声認識)(IBM)
https://www.ibm.com/watson/jp-ja/developercloud/speech-to-text.html - 次世代のインターフェース「音声認識」がもたらす、人間とコンピューターの新たな関係性(mugendai)
https://www.mugendai-web.jp/archives/8707 - Historic Achievement: Microsoft researchers reach human parity in conversational speech recognition(マイクロソフト)
- https://blogs.microsoft.com/ai/historic-achievement-microsoft-researchers-reach-human-parity-conversational-speech-recognition/#sm.00009tsoxbv4ofehry427ltdt918l
- WatsonをIoTの頭脳に、IBMの狙いは(COMPUTERWORLD)
https://tech.nikkeibp.co.jp/it/atcl/idg/14/481542/102500430/?ST=cm-software&P=2 - 米国株ランキング 時価総額(Yahoo!ファイナンス)
https://stocks.finance.yahoo.co.jp/us/ranking/?kd=4&tm=d&mk=&adr=&cg=&idx=&brk=&p=1 - IBM Watsonとは? 豊富な活用実績で、どんなビジネスにも対応(IBM)
https://www.ibm.com/watson/jp-ja/what-is-watson.html
役にたったらいいね!
してください
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。






