
自然言語処理で世界をリードする、先進的な英国のスタートアップ
ディープラーニングのブレイクスルーを皮切りに、人工知能(AI)の活躍の場は、今なお拡大の一途をたどっている。日本でも海外でも、独自開発のAIを武器とした多くのスタートアップ企業が誕生し、多様なサービスを展開している。
そんなスタートアップ企業の一つに、英・ロンドンに本拠を置くPhrasee社がある。Phrasee社は、主に自然言語、つまり人間が普段使っている言葉にAIの先進的な手法を適用し、独自のアルゴリズムを開発した。そのAIの自然言語理解・生成技術を活かし、特にメールにおけるマーケティングの仕事を助ける事業を展開している。
このPhrasee社のサービスは具体的にはどんなものなのか、新しい自然言語処理は、どのような仕組みで動いているのかを掘り下げてみよう。
Phrasee社とは
“Phrasee is pretty crazy”と、公式サイトで自らを”クレイジー”だというPhrasee社。2015年2月23日の創業という、本当に若いスタートアップ企業だ。
特に電子メールを使ったマーケティングにおいて、AIを使ってイノベーションを起こしている売り出し中の会社のようで、2016年7月にはギャルヴァニス・キャピタルから100万ドルを資金調達したという。
主なサービスとしては、メールのタイトル文などを、ユーザーの興味を引き出しクリック行動へ誘導するように最適化して自動生成するサービスがある。また、Phrasee Pheelingsという言語を解析するためのツールでは、ユーザーの感情を分析を行い、どうすればユーザーのリアクションに導けるかを学習・予測する。
このように、Phrasee社は特にマーケティング担当者向けに人工知能システムを提供している。自然言語生成技術には相当な自信をもっている様子で、この分野では世界をリードしている、と公式サイトでは自ら謳っているほどだ。
この会社のチーフサイエンティストのNeil Yager Ph.Dは多くのデータマイニングの本を書いていて、イノベーション賞という権威のある賞も受賞しているという。ニューラルネットワークを用いた言語生成の記事も公開している。

読者に読んでもらえる広告メールを自動で生成
Phrasee社のサービスは、メールのタイトルや本文、つまり英語など人間が使う自然言語を”最適化”して自動生成する。ここでいう”最適化”とは、メールを見たユーザーにいかに興味を惹かせ、クリックを促せるかをAIが学習していくことを指す。もちろん最初は英語から研究が開始されたが、次々に他国語にも対応してきている。
恐らく電子メールを使っている誰もが経験していることだろうが、従来の広告メールでは、タイトルから明らかに一律のコピペ文だったりして、ユーザーが広告メールだと即時にわかったりすることが多い。ユーザーが興味のないメールは、すぐにゴミ箱に捨てられるだろうし、その前に迷惑メールフィルタによってユーザーの目に触れるまでも行かずに捨てられてしまう。
しかし、Phrasee社の言語生成技術では、人間が一つ一つ書いたかのような自然な言葉遣いを、AIが書くのだという。公式サイトの記述によると、その精度は98%だという。実際に人間が手作業で書くよりも、良い販促効果が期待できるようだ。
自然言語理解・生成方法の大きな流れの転換
Phrasee社が独自に開発しているという”natural language generation”(NLG, 自然言語生成)アルゴリズムは、ディープラーニングを使った統計的な手法だという。
人工知能の自然言語処理や機械翻訳の歴史上は、論理的な文構造の分析から言語を理解・生成する仕組みが研究されてきた。
しかし、論理アプローチでの自然言語理解・生成方法では、ある程度限界が見えてきていた。言語は論理的な構文(Syntax)に従うものとして、人為的に構文パターンを入力するなどの膨大な人的手間を消費しながらも、思うような成果をあげられないでいた。自然言語の文法は、論理だけでは手に負えないのだ。
近年になってGoogle翻訳などで論理的アプローチとはことなる、統計的・確率的な自然言語処理・機械翻訳が採用されるなど、統計的アプローチの研究が盛んになってきた。(統計的アプローチでの自然言語の研究の起源は、コンピュータ以前からあったそうだ。)
Phrasee社の開発したアルゴリズムも、統計的な手法による言語生成を行う。ここでは、統計的な自然言語処理手法の一つ、word2vecがどのような仕組みで動いているのかについて、プログラムを動かした結果を見ながら説明したい。
word2vecとは? コンピュータは、”意味”をどうやって理解する?
word2vecとは、近年で少し話題になった面白い言語処理のモデルだ。ざっくりいうと、単語間の距離を分析して数値化する手法で、単語の意味を数字で表現する。
恐らく今までの多くの人が、言葉(単語、名前、概念)の意味や価値というものはそのモノ自身が性質として持っているように思っている人が多いのではないだろうか。しかし、どうも意味は全体の中のモノの位置や他の単語との関係性といった、外的な要因で決められる面が強いようだ。
その外的な要因を数字として表現・分析して、その単語の意味を割り出す具体的な方法のひとつがword2vecだ。word2vecの場合、ある単語間の距離をpositiveとnegativeで測る。
word2vecに与えたデータによって、言葉の距離・意味は変わる。つまり、意味はその文脈(context)に依存する、ということだ。私達が一般的だと思っているような単語の意味に対し、機械の単語の意味を近づけていくには、広い分野の膨大なテキストを処理させる必要がある。そうすれば人間の認識との比較でも、ある程度の精度を高めることができる。
ただし、単語に数字を割り当てることで、本当に意味がわかっていることになるのかというのは疑問だ。「リンゴ」という文字列に、赤くて丸い物質の”イメージ”は紐付いていない。単語間の距離を数字にしただけで”意味”がわかったということには、やはりならないだろう。しかし、数字しか扱えないコンピュータなりに意味を理解させるための一つの方法として、ある程度は有効だ。
また、word2vecには、単語を数字にすることで、「単語間の演算」が可能になるという面白い効果がある。
『三国志』の登場人物の人間関係を測ってみる!?
word2vecは大量のデータを与えないと、単語の意味の精度は落ちる。しかし逆に、ある少量のテキストをデータとして与えれば、そのテキストの文脈や雰囲気のようなものがわかってくる面もある。
今回試してみたのは、青空文庫の『三国志』だ。
吉川英治の『三国志』の第6巻”赤壁の巻”の1冊文のテキストをword2vecで処理させてみた。”赤壁の巻”という文脈の上で、”孔明”という単語で遊んでみる。もしかしたら、孔明と周瑜や曹操との人間関係がpositiveまたはnegativeな距離として測れる、つまり、人間関係を分析できるかも知れない。
もちろんコンピュータには、”孔明”とは諸葛亮孔明のことだとか、劉備や曹操との関係なども知らない。それどころか、孔明が人間であることさえもわかっていない。word2vecに1冊分の小説データを与えただけで、どれだけコンピュータが”ゼロから意味を作る”ことができるのだろうか・・・。
まず、”孔明”とpositiveな関係の単語Best10だ。
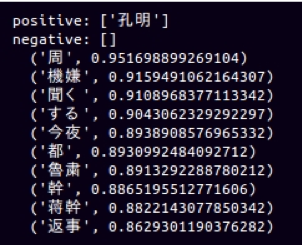
左の文字が単語名、右の数字が”孔明”との近さを表し、上下に近さ準に並んでいる。”魯粛”(孔明の蜀とは同盟関係の呉の配下)で、友好関係にあった人物名だ。たしかに、孔明と魯粛はpositiveな関係であることが、word2vecで認識できているようだ。また、最初の”周”は、呉の軍師”周瑜”を表しているようだ。
日本語は英語のように空白で区切らず、コンピュータは単語の区切りがわからない。word2vecの処理の前に、”形態素解析”を行い、予め単語を分ける必要が日本語の場合はあるが、その時に”周瑜”が”周”と”瑜”に分けられてしまったようだ。この形態素解析のように、日本語は英語などの言語とは大きく特徴が違っているため、英語とは違ったアプローチが必要になってくる。
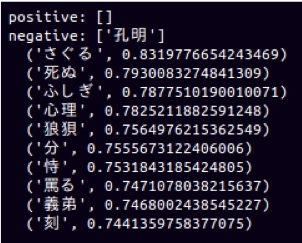
今度は、”孔明”とnegativeな関係にある単語だ。”死ぬ”、”狼狽”,”罵る”と言ったネガティブな言葉が、確かに認識されている。”曹操”の場合はどうだろうか。
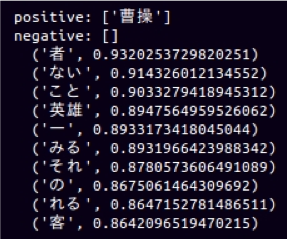
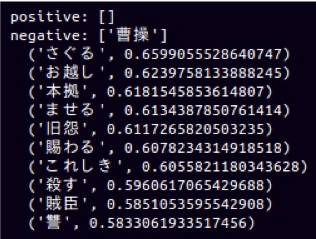
“曹操”のpositiveな関係には、”英雄”という単語が見える。またnegativeの方には、”旧怨”, “賊臣”, “殺す”などの単語が見える。word2vecは、曹操の意味・特徴をとてもよく捉えている。
さらにword2vecの面白いところは、単語で演算ができるところだ。たとえば、「 “孔明” + “魯粛” – “曹操” = ??? 」というように、加算や減算を単語に対して行える。上記の計算を行った結果は、以下の通りだ。
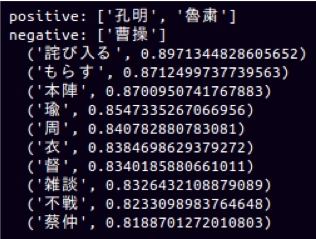
“周”, “瑜”の文字が見える。やはり、”周瑜”の分かち書きに失敗しているようだ。しかし、それでも周瑜が”赤壁の戦い”の頃には孔明や魯粛に近い位置にいるという特徴が捉えられている。
小説1冊分のテキストだけでも、word2vecは意外と頑張ってくれていた。単語としての意味だけでなく、人間関係の分析もできているように見える。もちろん、このような演算が行えることは、言語生成の助けになることだ。
自然言語処理は面白い
Phrasee社の得意とする自然言語処理機構は、新しい言語理解・生成手法の統計的アプローチによるものだった。なお、Phrasee社のサイトには、メールのタイトルだけではなく、コンピュータが生成した短編のSF小説も載っているので、興味のある方は読んでみてほしい。
ここでは統計的アプローチによる自然言語処理の画期的な方法としてword2vecを取り上げ、簡単にではあるが実際に試してみた。少ないデータでもword2vecは威力を発揮してくれている様子を見た。ある特定の”文章の世界”内での人間関係の分析という、面白そうなテーマにもword2vecは使えそうだ。
少しでも自然言語処理の面白さの一端を伝えられていたとしたら、幸いである。

<参考>
- Phrasee: The Future of Email Marketing(Techround)
https://techround.co.uk/business/2017/14/12/phrasee/ - Email Marketing AI to Boost Your Email Marketing Campaigns(Phrasee)
https://phrasee.co/ - 注目のAIスタートアップ10選 節電アプリVerv、人材発掘のJamieAiなど 英国編(ZUU online)
https://zuuonline.com/archives/181437 - Neural text generation – Phrasee – (Medium Neil Yager)
https://medium.com/phrasee/neural-text-generation-generating-text-using-conditional-language-models-a37b69c7cd4b - Sci-fi short story written by Phrasee’s natural language generation AI(Phrasee)
https://phrasee.co/sci-fi-short-story-written-phrasees-natural-language-generation-ai/ - 計量文献学(Wikipedia)
https://ja.wikipedia.org/wiki/計量文献学 - How it works(Phrasee)
https://phrasee.co/how-it-works/ - 『深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ)』 (坪井祐太、 海野裕也 他著)
役にたったらいいね!
してください
NISSENデジタルハブは、法人向けにA.Iの活用事例やデータ分析活用事例などの情報を提供しております。






