Facebook AI Researchが開発したfastTextは自然言語処理を高速、高精度化するために有効な機械学習ライブラリである。本記事では、fastTextの仕組みと、活用した場合に広がる可能性について述べる。
続きを読むfastTextで何ができるようになるのか
fastTextはFacebook AI Researchが2016年に開発した自然言語処理向けアルゴリズムであり、GitHubにてオープンソースとして公開している単語のベクトル化とテキスト分類をサポートした機械学習ライブラリである。同様のアルゴリズムとしては、当時Googleに在籍していたTomas Mikolov(fastText開発者の一人)によって2013年に論文として発表されたWord2Vecがある。fastTextという名前の通りWord2Vecを含む他のアルゴリズムに比較して、動作が軽く速いのが特徴である。FacebookのAI Researchのサイトでは、他のアルゴリズムは何時間もかかっているところを数十秒で処理が完了したと述べている。さらに精度についても向上している。
fastTextのリリースにより、自然言語処理導入のハードルが格段に下がったと言っても過言ではない。

(表: Facebook research より転載)
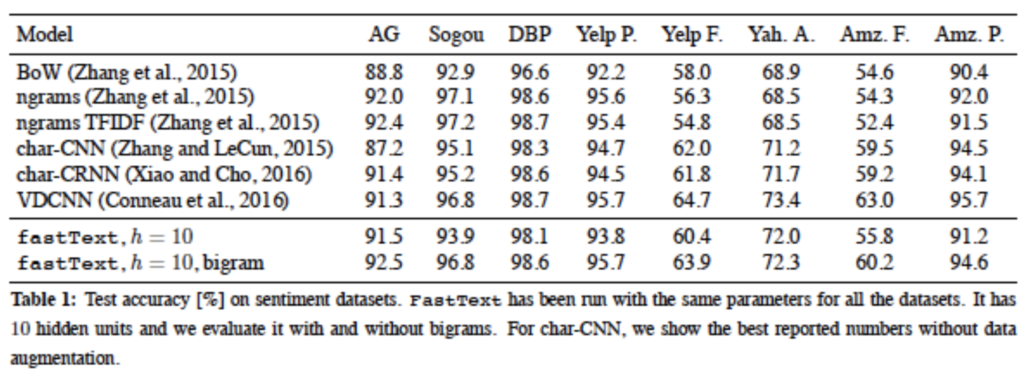
(表:semanticscholar.orgより転載)

fastTextの仕組み
自然言語処理では、コンピュータで処理するために、言語を数値的に表現する必要がある。その表現方法の基礎が単語のベクトル化である。単純なベクトル化の手法としてはone-hotという手法がある。one-hotは、処理対象となる文全体で利用される単語ひとつひとつに対してそれぞれ一つの次元を割り当てる方法である。例えば、
I am a son.
You are a father.
という例文を考える。この2文を対象とした場合、単語は7個あり、全ての単語はone-hot表現では7次元ベクトルで表現される、
I = [1,0,0,0,0,0,0]
am = [0,1,0,0,0,0,0]
a = [0,0,1,0,0,0,0]
son = [0,0,0,1,0,0,0]
you =[0,0,0,0,1,0,0]
are =[0,0,0,0,0,1,0]
father =[0,0,0,0,0,0,1]
となる。この様に単語をベクトル化すると、
You are a son
という新しい文はベクトル表現では、
[0,0,0,0,1,0,0] +[0,0,0,0,0,1,0]+ [0,0,1,0,0,0,0]* [0,0,0,1,0,0,0]
=[0,0,1.1,1,1,0]
と表現される。
one-hot表現はわかりやすく便利であるが、基になる文章が大量になる場合、単語が多様となり表現ベクトルの次元が大きくなることが問題点である。例えば1文あたり10単語の文章の判別問題であっても、基の単語の数が100万語である場合、one-hotでは、100万次元という非常に高次元ベクトルになるため、メモリサイズを超えてしまいGPUを利用することができなくなってしまう。
それに比較して、fastTextの単語のベクトル化は、文章を構成する単語を複数の特徴に対する関連の度合いを0〜1の間の実数で表現するものである。したがって、基になる文章の量が多く、取り扱う分野が多くとも、このベクトルは高次元でも256次元以上、つまり特徴の項目数が256個以上程度となる。fastTextはディープラーニングを用いてテキストデータからベクトル化されたモデルを獲得する。
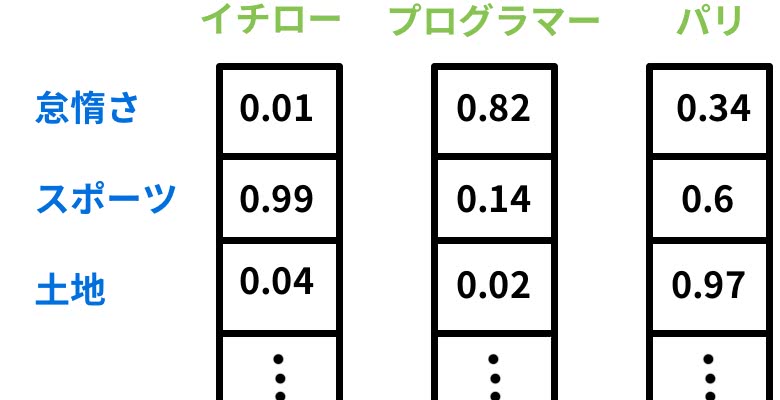
(図: DeepAgeより転載)
また、テキスト分類とは、単語のベクトルを用いて同じ特徴の数値が高い単語をそれぞれのグループに分類することである。テキスト分類の基本的なアルゴリズムは、2値分類タイプのSVM(Support Vector Machine)やNaïve Bayesianがこれまで標準的であった。しかし、これらのアルゴリズムをマルチクラスの問題や不均衡データに活用しようとすると非常に処理負荷が高くなるという問題があった。それに対してfastTextは、テキストの分類にCBOW(Continuous Bag-of-Words )、skip-gramの2種類のアルゴリズムをニューラルネットワーク上で実現している。
CBOW
CBOWは文章の中にある単語を前後の単語から推測するために利用されるモデルを生成する。文章のある位置にある単語が出力で、その単語の前後の単語からなる配列が入力となる。
skip-gram
skip-gramはCBOWとは逆に、文章のある単語から、その前後に出てくる単語を推測するモデルを生成するアルゴリズムである。入力はある位置にある単語とその一部からなる配列であり、出力はその前後に出てくる単語となる。前後にでてくる単語は複数あるので、学習はそれぞれ実施する。
CBOWとskip-gramの使い分けは、CBOWはデータ量が比較的少ない場合、有用であり、skip-gramはデータ量が大きい場合に有用であると言われている。
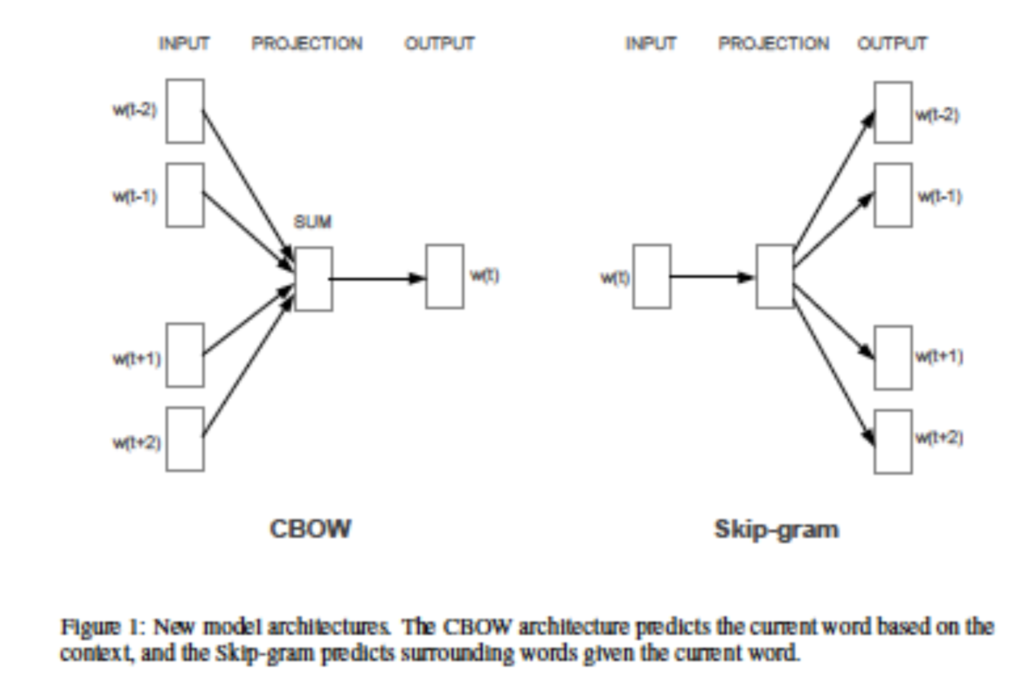
(図:Efficient Estimation of Word Representations in Vector Space より転載)
ここで一点注意したいのは、fastTextはどの言語にも適用可能であるが、日本語は単語の切れ目が明確でないため日本語に適用する場合は、fastTextでの処理の前に個々の単語を区別する“分かち書き”処理を実行する必要があるということである。分かち書き処理にはMeCab(めかぶ)というオープンソースの形態素解析エンジンが利用されることが多い。
fastTextの具体的な活用方法
fastTextは自然言語処理の基本的な処理を高速、高精度化するアルゴリズムであるため、様々な活用方法が考えられるが、代表的な活用方法を以下に示す。
記事のカテゴリ分類
大量の記事に対して、“政治系”、“経済系”、“社会系”、“文化系”などのカテゴリ別ラベルをつけ、CBOWまたはSkip-gramにて教師付き学習を行いモデルを構築する。そのモデルを活用することで新たな記事に対するカテゴリ分類が自動化可能となる。
文章の感情分析(Positive/Negativeなど)
企業やサービスに関するユーザーアンケートの自由記述欄やTwitter、Facebookの様なSNSなどの大量の自由形式の文章に対して、“好意的(Positive)”,”否定的(Negative)”などに分類しラベルを付けて教師付き学習を行いモデルを構築する。そのモデルを活用することで企業やサービスに対する感情や評判の分析を自動化することが可能となる。
スペルミスなどの誤記チェック、修正提案
fastTextの単語のベクトル化を活用し単語同士の類似度を表現する共起関係をチェックすることで、出現確率が低い単語を誤記と判定することが可能となる。
流行語の抽出、流行の度合いの時間変化の計測
TwitterなどのSNSの文章を解析し単語の頻出度や、単語同士の共起関係をチェックすることで流行語が抽出でき、どのような使われ方をしているかの変化を時系列で認識することが可能となる。
まとめ
Facebook AI Researchが開発したfastTextは従来の自然言語処理に比較して大幅に高速、高精度な処理を提供する械学習ライブラリである。fastTextにより様々な文章やSNSの解析・分類することが可能となる。製品やサービスのマーケットでの評判の分析やマーケットでの流行分析が容易になる等ビジネスシーンでの利用が期待される。

<参考>
- Aidemy Tech Blog
自然言語処理の精度を向上させた”単語のベクトル表現”とは?簡単に実装してみた
http://blog.aidemy.net/entry/2017/07/01/184421 - DeepAge〜Facebookが公開した10億語を数分で学習するfastTextで一体何ができるのか
https://deepage.net/bigdata/machine_learning/2016/08/28/fast_text_facebook.html - fastText〜Faster, better text classification!
https://research.fb.com/fasttext/ - Bag of Tricks for Efficient Text Classification
- (Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov)
- Efficient Estimation of Word Representations in Vector Space
- (Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean)
- 機械学習で大量のテキストをカテゴリ別に分類してみよう
http://tech.wonderpla.net/entry/2017/10/10/110000
役にたったらいいね!
してください
No related posts.






